1. ņä£ ļĪĀ
ņ×¼ļŻīņØś ļ»ĖņäĖņĪ░ņ¦ü Ļ┤Ćņ░░ņØĆ ĻĖłņåŹĻ│╝ ĒĢ®ĻĖłņØä ĒżĒĢ©ĒĢ£ ņ×¼ļŻīĻ│ĄĒĢÖ ņŚ░ĻĄ¼ņØś Ļ░Ćņן ĻĖ░ņ┤łĻ░Ć ļÉśļŖö ļÅäĻĄ¼ņØ┤ļŗż. ĻĘĖņżæ Ļ┤æĒĢÖĒśäļ»ĖĻ▓ĮņŚÉ ņØśĒĢ£ Ļ┤Ćņ░░ņØĆ ņŗ£ĒÄĖņØś ņżĆļ╣äĻ░Ć Ļ░äļŗ©ĒĢśļ®░ ļ░®ļ▓ĢņØ┤ ņÜ®ņØ┤ĒĢśĻ│Ā Ļ│Āņ░░ņØ┤ ņ¦üĻ┤ĆņĀüņØĖ ļ░®ļ▓ĢņØ┤ļŗż. ņŚ░ļ¦łņÖĆ Ļ┤æĒāØ Ļ│╝ņĀĢņØä Ļ▒░ņ╣£ ņŗ£ĒÄĖņØä ĒÖöĒĢÖņĀüņ£╝ļĪ£ ļČĆņŗØņŗ£ņ╝£ Ļ▓░ņĀĢļ”ĮĻ│äņÖĆ ņĀ£2ņāü ņ×ģņ×ÉļōżņØś Ļ┤Ćņ░░ņØ┤ Ļ░ĆļŖźĒĢśļŗż. ĒÖĢļīĆ ļ░░ņ£©ņØĆ ļīĆļץ ├Ś 50~├Ś 1000 ņĀĢļÅäņØ┤ļŗż. ņØ┤ļĢī Ļ┤Ćņ░░ļÉ£ ĻĖłņåŹņØś ļ»ĖņäĖņĪ░ņ¦üņØĆ ĒĢ®ĻĖłņØś ņä▒ļČäĻ│╝ ņĀ£ņĪ░ Ļ│ĄņĀĢņŚÉ ņØśĒĢśņŚ¼ Ļ▓░ņĀĢļÉśļ®░, ņĄ£ņóģņĀüņØĖ ļ¼╝ļ”¼ņĀü ĻĖ░Ļ│äņĀü ĒŖ╣ņä▒ņØä ņäżļ¬ģĒĢśļŖöļŹ░ņŚÉ ņé¼ņÜ®ļÉ£ļŗż. ĻĘĖļ¤¼ļ»ĆļĪ£ ļ»ĖņäĖņĪ░ņ¦ü Ļ┤Ćņ░░ņØĆ Ēśäņ×¼Ļ╣īņ¦ĆņØś ĻĖłņåŹ ņ×¼ļŻīņØś ņŚ░ĻĄ¼ņŚÉņä£ ņŚåņ¢┤ņä£ļŖö ņĢłļÉĀ Ļ░Ćņן ņżæņÜöĒĢ£ ļČäņäØ ĻĖ░ļ▓Ģ ņżæņØś ĒĢśļéśņØ┤ļŗż [1].
Ļ┤æĒĢÖĒśäļ»ĖĻ▓ĮņØä ĒåĄĒĢśņŚ¼ ņ¢╗ņ¢┤ņ¦ä ļ»ĖņäĖņĪ░ņ¦ü ņØ┤ļ»Ėņ¦ĆļŖö ņĀĢļ¤ēņĀü, ņĀĢņä▒ņĀü ļ░®ļ▓Ģņ£╝ļĪ£ ļČäņäØĒĢ£ļŗż. Ļ▓░ņĀĢļ”ĮņØ┤ļéś ņĀ£2ņāüņØś Ēü¼ĻĖ░ņÖĆ ļČäĒż ļō▒ņØś ņĀĢļ¤ēņĀü ļČäņäØņØĆ ĒÖöņāüļČäņäØ(image analysis) ņåīĒöäĒŖĖņø©ņ¢┤ļź╝ ĒåĄĒĢśņŚ¼ ļ╣äĻĄÉņĀü ņēĮĻ▓ī ņ×ÉļÅÖņĀüņ£╝ļĪ£ ļČäņäØĒĢĀ ņłś ņ׳ļŗż. ļśÉĒĢ£ ņČöĻ░ĆņĀüņØĖ ņŻ╝ņé¼ņĀäņ×ÉĒśäļ»ĖĻ▓Į(scanning electron microscope)Ļ│╝ Ēł¼Ļ│╝ņĀäņ×ÉĒśäļ»ĖĻ▓Į(transmission electron microscope), ņĀäņ×É ĒöäļĪ£ļĖī ļ»Ėļ¤ē ļČäņäØĻĖ░(electron probe micro-analyzer) ļō▒ņØä ĒåĄĒĢśņŚ¼ ņĀĢļ¤ēņĀüņØĖ ĒÖöĒĢÖ ņä▒ļČä ļČäņäØņØ┤ Ļ░ĆļŖźĒĢśļŗż. ĒĢ£ĒÄĖ ņĀĢņä▒ņĀüņØĖ ļČäņäØņØĆ ņØ╝ņ░©ņĀüņ£╝ļĪ£ ņ£ĪņĢł(Ķéēń£╝)ņ£╝ļĪ£ ņØ┤ļŻ©ņ¢┤ņ¦ĆĻ│Ā ņ׳ņ£╝ļ®░ ņØĖĻ░äņØś Ļ▓ĮĒŚśĻ│╝ ņ¦üĻ┤ĆņØä ĒĢäņÜöļĪ£ ĒĢ£ļŗż.
ņ╗┤Ēō©Ēä░ļź╝ ņØ┤ņÜ®ĒĢ£ ņĀĢņä▒ņĀüņØĖ ļ»ĖņäĖņĪ░ņ¦ü ļČäņäØņØś ņ×ÉļÅÖĒÖöļŖö ņĄ£ĻĘ╝ Ļ░üĻ┤æļ░øĻ│Ā ņ׳ļŖö ĻĖ░Ļ│äĒĢÖņŖĄņØä ņØ┤ņÜ®ĒĢśļ®┤ Ļ░ĆļŖźĒĢĀ Ļ▓āņ£╝ļĪ£ ņśłņāüļÉśļ®░ ņØ┤ņŚÉ ļīĆĒĢ£ ņŚ░ĻĄ¼Ļ░Ć ņ¦äĒ¢ēļÉśņ¢┤ņÖöļŗż [2-4]. 4ņ░© ņé░ņŚģņŚÉ ņĀæņ¢┤ļōżļ®┤ņä£ ņ╗┤Ēō©Ēä░ņØś ļ░£ņĀäņØĆ ņØĖĻ░äņØś ņśżĻ░ÉņØä ĻĖ░ņżĆņ£╝ļĪ£ ļ░£ļŗ¼ļÉśĻ│Ā ņ׳ņ£╝ļ®░, ĒŖ╣Ē׳ ņØ┤ļ»Ėņ¦Ć ļŹ░ņØ┤Ēä░ļź╝ ĒåĀļīĆļĪ£ ņŗ£Ļ░üņĀü Ļ░ÉĻ░ü ņŗżĒśäņØä ĻĄ¼ĒśäĒĢśĻ│Āņ×É ļ¦īļōżņ¢┤ņ¦ä ņĢīĻ│Āļ”¼ņ”śņØä ņØ┤ņÜ®ĒĢśņŚ¼ ņØĖĻ│Ąņ¦ĆļŖź ļ░Å ĻĖ░Ļ│äĒĢÖņŖĄņØ┤ ņŻ╝ļĪ£ ļ░£ļŗ¼ĒĢśņśĆļŗż. ņØ┤ļ»Ėņ¦Ć ļŹ░ņØ┤Ēä░ļź╝ ĒåĄĒĢ┤ ļ¦īļōżņ¢┤ņ¦ä ļöźļ¤¼ļŗØ ņĢīĻ│Āļ”¼ņ”ś ņżæ ņØ┤ļ»Ėņ¦Ć ņØĖņŗØ ļ░Å ļČäļźśņŚÉ ĒÜ©Ļ│╝ņĀüņØĖ ņä▒ļŖźņØä ļ│┤ņŚ¼ņżĆ ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦Ø(convolutional neural network, CNN)[5]ņØĆ ņŚ¼ļ¤¼ ļČäņĢ╝ņŚÉ ņĀüņÜ®ĒĢśņŚ¼ ņåÉĻĖĆņö© ļČäļźś, Ēö╝ļČĆņĢö Ļ▓Ćņ¦ä ļ░Å CT ņ┤¼ņśüļ│ĖņØä ĒĢÖņŖĄ ļŹ░ņØ┤Ēä░ļĪ£ ņØ┤ņÜ®ĒĢśņŚ¼ ņ¦äļŗ© ņä£ļ╣äņŖżļź╝ ņśłņĖĪĒĢśĻ▒░ļéś CCTV ņåŹ Ē¢ēļÅÖ ņØĖņŗØņØä ĒåĄĒĢ┤ ļ░®ļ▓ö ĒÖ£ļÅÖ ļō▒ ņÜ░ļ”¼ ņāØĒÖ£ ņåŹ ĒÄĖļ”¼ĒĢ© ļ░Å ļ¼ĖņĀ£ ļ░£ņĀäņŚÉ Ēü░ ļÅäņøĆņØ┤ ļÉśĻ│Ā ņ׳ļŗż. ņØ┤ CNNņØä ĻĖ░ņ┤łļĪ£ ĒĢśņŚ¼ ņØĖņģēņģś(Inception) [6]Ļ│╝ ĻĄ¼ĻĖĆļäĘ(GoogLeNet) [7], ļĀłņŖżļäĘ(ResNet) [8] ļō▒ņØś ņĢīĻ│Āļ”¼ņ”śņØ┤ ĒīīņāØļÉśņŚłļŗż. ņØ╝ļ░śņĀüņ£╝ļĪ£ ņØĖĻ│ĄņŗĀĻ▓Įļ¦Ø(artificial neural network) [9-11]ņØĆ ņł½ņ×É ļŹ░ņØ┤Ēä░ļź╝ ĻĖ░ļ░śņ£╝ļĪ£ ļŗżņłśņØś ļģĖļō£ļĪ£ ĻĄ¼ņä▒ļÉ£ ņØĆļŗēņĖĄ Ēś╣ņØĆ ņżæĻ░äņĖĄĻ│╝ ņ×ģļĀźņØä ļŗ┤ļŗ╣ĒĢśļŖö ņ×ģļĀźņĖĄ, ņČ£ļĀź Ļ▓░Ļ│╝ļź╝ ļéśĒāĆļé┤ļŖö ņČ£ļĀźņĖĄņ£╝ļĪ£ ĻĄ¼ņä▒ļÉ£ļŗż. ņĖĄ ņé¼ņØ┤ļŖö ņäĀĒśĢ ĒĢ©ņłśļĪ£ ņŚ░Ļ▓░ļÉśļ®░, Ļ░ü ļģĖļō£ņŚÉņä£ļŖö ĒÖ£ņä▒ĒÖö ĒĢ©ņłśļź╝ Ļ░¢Ļ▓ī ļÉ£ļŗż. ĻĖ░Ļ│äĒĢÖņŖĄņØĆ ņØ┤ ņŗĀĻ▓Įļ¦ØņŚÉņä£ ņé¼ņÜ®ĒĢśļŖö ĒĢ©ņłśņØś Ļ│äņłśļź╝ ņłśņ╣śņĀüņ£╝ļĪ£ Ļ│äņé░ĒĢśļŖö ĒśĢĒā£ļĪ£ ņ¦äĒ¢ēļÉ£ļŗż. ĻĖ░Ļ│äĒĢÖņŖĄ Ļ▓░Ļ│╝ņØś ņČ£ļĀźņØĆ ĒÜīĻĘĆļÉ£ ņłśņ╣ś Ļ▓░Ļ│╝ļéś ļČäļźśļĪ£ ļéśĒāĆļé£ļŗż. ņĀäņłĀĒĢ£ ļ░öņÖĆ Ļ░ÖņØ┤ ņØĖĻ│ĄņŗĀĻ▓Įļ¦ØņØĆ ņł½ņ×É ļŹ░ņØ┤Ēä░ļź╝ ĻĖ░ļ░śņ£╝ļĪ£ ĒĢśļŖöļŹ░, CNN ĻĖ░ļ░ś ņĢīĻ│Āļ”¼ņ”śņØĆ ņØ┤ļ»Ėņ¦Ćļź╝ ņ▓śļ”¼ĒĢśĻĖ░ ņ£äĒĢ┤ņä£ ņĖĄ ņé¼ņØ┤ļź╝ ņŚ░Ļ▓░ĒĢśļŖö ņäĀĒśĢ ĒĢ©ņłśļź╝ ļīĆņŗĀĒĢśņŚ¼ ĒĢ®ņä▒Ļ│▒(convolution)ņØä ņé¼ņÜ®ĒĢ£ļŗżļŖö ĒŖ╣ņ¦ĢņØ┤ ņ׳ļŗż. CNNņØä ĒżĒĢ©ĒĢ£ ņØĖĻ│ĄņŗĀĻ▓Įļ¦ØņØä ņØ┤ņÜ®ĒĢ£ ĻĖ░Ļ│äĒĢÖņŖĄņØĆ ņé¼ņÜ®ņØ┤ ņÜ®ņØ┤ĒĢśĻ│Ā ņĀĢĒÖĢļÅäĻ░Ć ļ¦żņÜ░ ļåÆņ£╝ļéś ņżæĻ░äņĖĄņŚÉņä£ņØś Ļ│╝ņĀĢņØĆ ņé¼ņÜ®ņ×ÉņŚÉĻ▓ī ļģĖņČ£ļÉśņ¦Ć ņĢŖļŖöļŗżļŖö ņ¢┤ļĀżņøĆņØ┤ ņ׳ļŗż. ņ”ē, ņ╗┤Ēō©Ēä░Ļ░Ć ļ»ĖņäĖņĪ░ņ¦ü ņØ┤ļ»Ėņ¦Ćļź╝ ņ▓śļ”¼ĒĢśļŖö Ļ│╝ņĀĢņŚÉņä£ ņØ┤ļ»Ėņ¦ĆņØś ņ¢┤ļ¢ż ĒŖ╣ņ¦ĢņØä ĻĖ░ņżĆņ£╝ļĪ£ ņØ┤ļ»Ėņ¦Ćļź╝ ļČäļźśĒĢśļŖöņ¦ĆļŖö ņĢīĻĖ░ ņēĮņ¦Ć ņĢŖļŗż. ļ│Ė ņŚ░ĻĄ¼ņ¦äņØĆ ņØ┤ņĀä ņŚ░ĻĄ¼ņŚÉņä£ CNN ņżæ ĒĢśļéśņØĖ ņØĖņģēņģśv3 (Inception-v3) ļ¬©ļŹĖņØä ņØ┤ņÜ®ĒĢśņŚ¼ Al-Si ĒĢ®ĻĖłņØś ņĪ░ņä▒ļ│äļĪ£ ļČäļźśĒĢśņśĆļŗż [12]. ņØĖņģēņģśv3 ļ¬©ļŹĖņØĆ ņżæĻ░äņĖĄ ĻĄ¼ņĪ░Ļ░Ć ļ│Ąņ×ĪĒĢśņŚ¼ ņØ┤ļ»Ėņ¦Ć ļČäļźśņØś ĻĖ░ņżĆņØä ņĢī ņłś ņŚåņŚłļŗż.
ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö Ļ░äļŗ©ĒĢ£ CNNņØä ĻĄ¼ņČĢĒĢśĻ│Ā, ĻĖ░Ļ│äĒĢÖņŖĄņØä ĒåĄĒĢśņŚ¼ ņŻ╝ņ▓ĀņØś ļ»ĖņäĖņĪ░ņ¦üņØä ļČäļźśĒĢśĻ│Āņ×É ĒĢśņśĆļŗż. ņØ┤ļĢī ņé¼ņÜ®ĒĢ£ ņŗ£ĒÄĖņØĆ ĻĄ¼ņāüĒØæņŚ░ņŻ╝ņ▓ĀĻ│╝ ĒÜīņŻ╝ņ▓ĀņØ┤ļ®░ ņØ┤ ļæÉ Ļ░Ćņ¦Ć ņŗ£ĒÄĖņØś ļ»ĖņäĖņĪ░ņ¦üņØä ĻĄ¼ļ│äĒĢśņŚ¼ ļČäļźśĒĢśļÅäļĪØ ĒĢśņśĆļŗż. ĻĄ¼ņāüĒØæņŚ░ņŻ╝ņ▓ĀĻ│╝ ĒÜīņŻ╝ņ▓ĀņØĆ ņ£ĪņĢłņ£╝ļĪ£ļÅä ņ¢┤ļĀĄņ¦Ć ņĢŖĻ▓ī ĻĄ¼ļ│äļÉ£ļŗż. ĻĘĖļ¤╝ņŚÉļÅä ļČłĻĄ¼ĒĢśĻ│Ā ņØ┤ ņŚ░ĻĄ¼ļź╝ ņ¦äĒ¢ēĒĢśļŖö ļ¬®ņĀüņØĆ, ņÜ░ļ”¼Ļ░Ć ņØĄĒ׳ ĻĄ¼ļ│äĒĢĀ ņłś ņ׳ļŖö ņē¼ņÜ┤ ļ»ĖņäĖņĪ░ņ¦üņØä ņØĖĻ│ĄņŗĀĻ▓Įļ¦ØņØ┤ ņ¢┤ļ¢╗Ļ▓ī ņØĖņ¦ĆĒĢĀ Ļ▓āņØĖĻ░Ćļź╝ ņĢīĻĖ░ ņ£äĒĢ©ņØ┤ļŗż. ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ ņé¼ņÜ®ĒĢ£ CNNņØś ņżæĻ░äņĖĄņŚÉņä£ņØś ņØ┤ļ»Ėņ¦Ćļź╝ ņŗ£Ļ░üĒÖöĒĢśņŚ¼ Ļ│╝ņŚ░ ņØĖĻ│ĄņŗĀĻ▓Įļ¦ØņØ┤ ņŻ╝ņ▓ĀņØś ļ»ĖņäĖņĪ░ņ¦üņØä ĻĄ¼ļ│äĒĢśļŖö Ļ▓āņŚÉ ņ׳ņ¢┤ņä£ ņ¢┤ļ¢ż ņĀÉņŚÉ ņżæņĀÉņØä ļæÉļŖöņ¦Ć ņĢīĻ│Āņ×É ĒĢśņśĆļŗż. ļśÉĒĢ£ ĻĖ░Ļ│äĒĢÖņŖĄņØ┤ ņØĖĻ░äņØś ņØĖņ¦Ćļź╝ ņĀ£ļīĆļĪ£ ļ¬©ļ░®ĒĢśĻ│Ā ņ׳ļŗżļŖö Ļ░ĆņĀĢĒĢśņŚÉ, ņØĖĻ░äņØ┤ ļ»ĖņäĖņĪ░ņ¦üņØä ņ¢┤ļ¢╗Ļ▓ī ņØĖņ¦ĆĒĢśļŖöņ¦ĆņŚÉ ļīĆĒĢ£ ļ¼ĖņĀ£ņØś ĒåĄņ░░ņŚÉļÅä ņĀüņÜ®ĒĢĀ ņłś ņ׳ņ£╝ļ”¼ļØ╝ ņśłņāüĒĢ£ļŗż.
2. ņØĖĻ│ĄņŗĀĻ▓Įļ¦Ø
2.1 ĒĢ®ņä▒Ļ│▒ņŗĀĻ▓Įļ¦Ø(CNN)
ĻĖ░Ļ│äĒĢÖņŖĄņŚÉ ņØ╝ļ░śņĀüņ£╝ļĪ£ ņé¼ņÜ®ļÉśļŖö ņØĖĻ▓ĮņŗĀĻ▓Įļ¦ØņØĆ Fig 1ņŚÉ ļéśĒāĆļéĖ ļ░öņÖĆ Ļ░ÖņØ┤ ņ×ģļĀźņĖĄ(input layer)Ļ│╝ ņØĆļŗēņĖĄ(hidden layer), ņČ£ļĀźņĖĄ(output layer)ļĪ£ ĻĄ¼ņä▒ļÉ£ļŗż. ņ×ģļĀźņĖĄņŚÉņä£ļŖö ļ│ĆņłśĻ░Ć ņł½ņ×É ĒśĢĒā£ļĪ£ ņ×ģļĀźļÉśļ®░, ņČ£ļĀźņĖĄņŚÉņä£ļŖö ļČäļźśļéś ĒÜīĻĘĆņŚÉ ļö░ļØ╝ ĻĘĖ Ļ▓░Ļ│╝Ļ░ÆņØä ņ¢╗ļŖöļŗż. ņØĆļŗēņĖĄņØĆ ņŚ¼ļ¤¼ ņĖĄņ£╝ļĪ£ ņØ┤ļŻ©ņ¢┤ņ¦ł ņłś ņ׳ņ£╝ļ®░, Ļ░ü ņĖĄņŚÉļŖö 1Ļ░£ ņØ┤ņāüņØś ļģĖļō£(node)ļĪ£ ĻĄ¼ņä▒ļÉ£ļŗż. Ļ░ü ļģĖļō£ņŚÉļŖö ļ╣äņäĀĒśĢņØś ĒÖ£ņä▒ĒÖöĒĢ©ņłś(activation function)Ļ░Ć ņĪ┤ņ×¼ĒĢ£ļŗż. ļśÉĒĢ£ Ļ░ü ļģĖļō£ļŖö ņØ┤ņĀä ņĖĄņØś ļ¬©ļōĀ ļģĖļō£ Ļ░ÆņØä ļ│ĆņłśļĪ£ ĒĢśļŖö ņäĀĒśĢĒĢ©ņłśļĪ£ ņĀĢņØśļÉ£ļŗż. ņØ┤ņÖĆ Ļ░ÖņØ┤ ļ¬©ļōĀ ļģĖļō£Ļ░Ć ņäĀĒśĢĒĢ©ņłśļĪ£ ņŚ░Ļ▓░ļÉśņ¢┤ ņ׳ļŖö ņŚ░Ļ▓░ĒśĢĒā£ļź╝ ņÖäņĀäņŚ░Ļ▓░Ļ│äņĖĄ(fully-connected layer)ņØ┤ļØ╝Ļ│Ā ĒĢ£ļŗż. Ļ░üņĖĄņØś ĒÖ£ņä▒ĒÖö ĒĢ©ņłśļŖö ļ│äļŗżļźĖ Ļ│äņłśĻ░Ć ņĪ┤ņ×¼ĒĢśņ¦Ć ņĢŖņ£╝ļ®░ ĒĢŁņāü ņØ╝ņĀĢĒĢśļŗż. ļ░śļ®┤ ņäĀĒśĢĒĢ©ņłśņØś Ļ│äņłśļŖö ĒĢÖņŖĄņ┤łĻĖ░ņŚÉļŖö ĒÖĢņĀĢļÉśņ¢┤ ņ׳ņ¦Ć ņĢŖļŖöļŹ░ ĻĖ░Ļ│äĒĢÖņŖĄĻ│╝ņĀĢņŚÉņä£ ņØ┤ Ļ│äņłśņØś Ļ░ÆņØ┤ ĒÖĢņĀĢļÉ£ļŗż.
ņØĖĻ│ĄņŗĀĻ▓Įļ¦ØņØä ļ░öĒāĢņ£╝ļĪ£ ĒĢ£ ņØ┤ļ»Ėņ¦Ć ņØĖņŗØņØś Ļ░Ćņן ĻĖ░ļ│ĖņĀüņØĖ ņśłļŖö MNIST (Modified National Institute of Standards and Technology) ļŹ░ņØ┤Ēä░ļ▓ĀņØ┤ņŖż [13]ļź╝ ņØ┤ņÜ®ĒĢśļŖö Ļ▓āņØ┤ļŗż. MNISTļŖö ņł½ņ×É 0~9ņŚÉ ļīĆĒĢ£ ņåÉĻĖĆņö©ņŚÉ ļīĆĒĢ£ ņØ┤ļ»Ėņ¦ĆņØś ļ¬©ņØīņØ┤ļŗż. ņØ┤ļ»Ėņ¦ĆļŖö 28 ├Ś 28 ĒöĮņģĆņØś ĒØæļ░▒ņØ┤ļ»Ėņ¦ĆļĪ£ņä£, ļŹ░ņØ┤Ēä░ļ▓ĀņØ┤ņŖżņŚÉļŖö 60,000Ļ░£ņØś ĒĢÖņŖĄņÜ® ļŹ░ņØ┤Ēä░ņÖĆ 10,000Ļ░£ņØś ņŗ£ĒŚśņÜ® ļŹ░ņØ┤Ēä░Ļ░Ć ņČĢņĀüļÉśņ¢┤ ņ׳ļŗż. ņØ┤ ņåÉĻĖĆņö© ņØ┤ļ»Ėņ¦Ćļź╝ ļČäļźśĒĢśļŖö Ļ░Ćņן ļŗ©ņł£ĒĢ£ ļ░®ļ▓ĢņØĆ, Ļ░ü ĒöĮņģĆņØś ļ¬ģņĢöņØä ņØ╝ļ░śņĀüņØĖ ņł½ņ×É(0~255)ļĪ£ ļ│ĆĒÖśĒĢśĻ│Ā 2ņ░©ņøÉ ļ░░ņŚ┤ļĪ£ Ēæ£ņŗ£ļÉ£ ņØ┤ļ»Ėņ¦Ćļź╝ ņł£ņ░©ņĀüņØĖ 1ņ░©ņøÉ ļ░░ņŚ┤ļĪ£ ļ│ĆĒÖśĒĢ£ ļŗżņØī, ņ£äņŚÉņä£ ņäżļ¬ģĒĢ£ ņØ╝ļ░śņĀüņØĖ ņØĖĻ│ĄņŗĀĻ▓Įļ¦ØņØś ņ×ģļĀźņĖĄ ļģĖļō£ņŚÉ Ļ░ü ĒöĮņģĆņØś ņł½ņ×Éļź╝ ņ×ģļĀźĒĢśņŚ¼ ĒĢÖņŖĄĒĢśļŖö Ļ▓āņØ┤ļŗż [14]. ņØ┤Ļ▓āņØĆ ņ¦üĻ┤ĆņĀüņØĖ ļ░®ļ▓ĢņØ┤ĻĖ┤ ĒĢśņ¦Ćļ¦ī, ņØ┤ļ»Ėņ¦Ć ļé┤ņØś ņé¼ļ¼╝ņØś Ļ│ĄĻ░äņĀüņØĖ Ļ┤ĆĻ│äņŚÉ ļīĆĒĢ£ ņČöļĪĀņØ┤ ļČĆņĪ▒ĒĢśĻ│Ā, ĒĢ┤ņāüļÅäĻ░Ć Ēü░ ņØ┤ļ»Ėņ¦Ć, ņśłļź╝ ļōżņ¢┤ 1000 ├Ś 1000 ĒöĮņģĆ ņØ┤ņāüņØś Ēü░ ņØ┤ļ»Ėņ¦ĆņØś Ļ▓ĮņÜ░ ņØĖĻ│ĄņŗĀĻ▓Įļ¦ØņØś ĻĘ£ļ¬©Ļ░Ć ņ¦Ćļéśņ╣śĻ▓ī ņ╗żņĀĖņä£ ņ╗┤Ēō©Ēä░ņØś ņÜ®ļ¤ēņØ┤ļéś ņåŹļÅäĻ░Ć Ēü¼Ļ▓ī ņśüĒ¢źņØä ļ»Ėņ╣Ā ņłś ņ׳ļŗż.
CNNļÅä ĻĖ░ļ│ĖņĀüņ£╝ļĪ£ ņ£äņŚÉņä£ ņäżļ¬ģĒĢ£ ņØĖĻ│ĄņŗĀĻ▓Įļ¦ØĻ│╝ ņ£Āņé¼ĒĢ£ ĻĄ¼ņĪ░ļź╝ Ļ░¢ļŖöļŗż. ņ×ģļĀźņĖĄņŚÉņä£ļŖö ļ│ĆņłśļĪ£ņä£ ņØ┤ļ»Ėņ¦Ćļź╝ ļīĆņ×ģĒĢ£ļŗż. ņČ£ļĀźņĖĄņŚÉņä£ļŖö ĻĖ░ļ│Ė ņØĖĻ│ĄņŗĀĻ▓Įļ¦ØĻ│╝ Ļ░ÖņØ┤ ļČäļźśļéś ĒÜīĻĘĆņŚÉ ļö░ļØ╝ ĻĘĖ Ļ▓░Ļ│╝Ļ░ÆņØä ņ¢╗ļŖöļŗż. ņØĆļŗēņĖĄņØĆ ĻĖ░ļ│Ė ņØĖĻ│ĄņŗĀĻ▓Įļ¦ØņØś ļģĖļō£ņÖĆ ņ£Āņé¼ĒĢśĻ▓ī ņ▒äļäÉņØä Ļ░Ćņ¦Ćļ®░ Ļ░ü ņ▒äļäÉņŚÉļŖö ņØ┤ļ»Ėņ¦Ć ņĀĢļ│┤Ļ░Ć ņĀĆņןļÉ£ļŗż. ņØ┤ņĀäņĖĄĻ│╝ Ēśäņ×¼ņĖĄņØ┤ ĒĢ®ņä▒Ļ│▒(convolution)ņ£╝ļĪ£ ņŚ░Ļ▓░ļÉ£ļŗżļŖö Ļ▓āņØ┤ļŗż. ĒĢ®ņä▒Ļ│▒ņØĆ ņØĖĻ│ĄņŗĀĻ▓Įļ¦ØņØś ņĖĄĻ░ä ņäĀĒśĢĒĢ©ņłśņÖĆ ņ£Āņé¼ĒĢ£ ņŚŁĒĢĀņØä ĒĢśļŖöļŹ░, ņäĀĒśĢĒĢ©ņłś ļīĆņŗĀ ņ×æņØĆ Ēü¼ĻĖ░ņØś ņØ┤ļ»Ėņ¦ĆņØĖ ĒĢäĒä░(filter)ļĪ£ ņØ┤ļŻ©ņ¢┤ņĀĖ ņ׳ļŗż. ņØ┤ ĒĢäĒä░ ņØ┤ļ»Ėņ¦ĆņØś ĒśĢĒā£ļŖö CNNņØś ĒĢÖņŖĄĻ│╝ņĀĢ ņżæ ĒÖĢņĀĢļÉ£ļŗż. ĒĢ®ņä▒Ļ│▒ņØ┤ ņØ┤ļŻ©ņ¢┤ņ¦Ćļ®┤ ņ×ģļĀźļŹ░ņØ┤Ēä░ļĪ£ļČĆĒä░ ĒŖ╣ņ¦ĢņØ┤ ņČöņČ£ļÉ£ļŗż. ĒĢ®ņä▒Ļ│▒ ņżæņŚÉ ņØ┤ļ»Ėņ¦ĆņØś Ēü¼ĻĖ░ļŖö ļ│ĆĒÖöĻ░Ć Ļ░ĆļŖźĒĢ£ļŹ░ ņØ╝ļ░śņĀüņ£╝ļĪ£ļŖö ņØ┤ļ»Ėņ¦Ćļź╝ ņČĢņåīĒĢ£ļŗż. ĒĢ®ņä▒Ļ│▒ ņŚ░ņé░ņŗ£ ņØ┤ļ»Ėņ¦ĆņØś ņČĢņåīĻ│╝ņĀĢņØä ņĪ░ņĀłĒĢśĻĖ░ ņ£äĒĢśņŚ¼ ņČöĻ░ĆņĀüņ£╝ļĪ£ Ēī©ļö®(padding)Ļ│╝ ņŖżĒŖĖļØ╝ņØ┤ļō£(stride)ļź╝ ņĀüņÜ®ĒĢśĻĖ░ļÅä ĒĢ£ļŗż. ņØ┤ Ļ│╝ņĀĢņŚÉņä£ ņ×ģļĀźļÉ£ ņØ┤ļ»Ėņ¦Ć(WI ├Ś HI)ļĪ£ļČĆĒä░ ĒĢäĒä░(WF ├Ś HF)ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ņČĢņåīļÉ£ ņØ┤ļ»Ėņ¦ĆņØś Ēü¼ĻĖ░(WO ├Ś HO)ļŖö ļŗżņØīĻ│╝ Ļ░ÖņØ┤ Ļ│äņé░ĒĢĀ ņłś ņ׳ļŗż [15].
ņØ┤ ņŗØņŚÉņä£ PņÖĆ SļŖö Ļ░üĻ░ü Ēī©ļö®Ļ│╝ ņŖżĒŖĖļØ╝ņØ┤ļō£ņØ┤ļŗż. ĒĢ®ņä▒Ļ│▒ ņŚ░ņé░ņØä ļ¦łņ╣£ ļŹ░ņØ┤Ēä░ļŖö ĒÖ£ņä▒ĒÖöĒĢ©ņłśļź╝ Ļ▒░ņ│É ĒÆĆļ¦ü(pooling)ņŚ░ņé░ņ£╝ļĪ£ ņŚ░Ļ▓░ļÉ£ļŗż. ĒÆĆļ¦üņØĆ ņČöĻ░ĆņĀüņ£╝ļĪ£ ņØ┤ļ»Ėņ¦Ćļź╝ ņČĢņåīņŗ£ĒéżļŖö ņŚŁĒĢĀņØä ĒĢśļ®░, ĒÆĆļ¦ü ĻĄ¼ņŚŁ ļé┤ņŚÉ ņĄ£ļīĆĻ░Æņ£╝ļĪ£ ņ¦ĆņĀĢĒĢśļŖö ņĄ£ļīĆĒÆĆļ¦ü(max pooling)Ļ│╝ ĒÅēĻĘĀĻ░ÆņØä ņ¦ĆņĀĢĒĢśļŖö ĒÅēĻĘĀĒÆĆļ¦ü(average pooling)ņØ┤ ņ׳ļŗż. ĒÆĆļ¦üņØä ĒĢĀ ļĢīņŚÉļÅä Ēī©ļö®Ļ│╝ ņŖżĒŖĖļØ╝ņØ┤ļō£ļź╝ ņ¦ĆņĀĢĒĢĀ ņłś ņ׳ļŖöļŹ░, ņØ┤ļĢī ņČĢņåīļÉ£ ņØ┤ļ»Ėņ¦ĆņØś Ēü¼ĻĖ░ļŖö ņ£äņØś Eq. 1ņŚÉņä£ ĒĢäĒä░ņŚÉ ĒÆĆļ¦ü ĻĄ¼ņŚŁņØś Ēü¼ĻĖ░ļź╝ ļīĆņ×ģĒĢśļ®┤ ņ¢╗ņØä ņłś ņ׳ļŗż. Ļ░ü ņŚ░ņé░ņŚÉ Ļ┤ĆĒĢ£ ņ×ÉņäĖĒĢ£ ļé┤ņÜ®ņØĆ ņ░ĖĻ│Āļ¼ĖĒŚī [15,16]ņØä ņ░ĖņĪ░ĒĢ£ļŗż.
ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ņ¦ĆĻĖłĻ╣īņ¦Ć ņäżļ¬ģĒĢ£ ĒĢ®ņä▒Ļ│▒Ļ│╝ ĒÖ£ņä▒ĒÖöĒĢ©ņłś, ĒÆĆļ¦ü ņŚ░ņé░ņØä ĒĢ®ņ│É ĒÄĖņØśņāüCP Ļ│äņĖĄņ£╝ļĪ£ ņ╣ŁĒĢ£ļŗż. ņØ┤ļ¤¼ĒĢ£ CP Ļ│äņĖĄņØä ņżæļ│Ą ņŚ░Ļ▓░ĒĢśĻ│Ā ņØ┤ļ»Ėņ¦ĆĻ░Ć ņČ®ļČäĒ׳ ņČĢņåīļÉśļ®┤, ņ£äņŚÉņä£ ņäżļ¬ģĒĢ£ MNISTņÖĆ Ļ░ÖņØ┤ ņØ╝ļ░ś ņØĖĻ│ĄņŗĀĻ▓Įļ¦ØņØĖ ņÖäņĀäĻ▓░ĒĢ®Ļ│äņĖĄ(FC)ņØä ĒåĄĒĢśņŚ¼ ņĄ£ņóģ ņČ£ļĀźņĖĄņ£╝ļĪ£ ņŚ░Ļ▓░ļÉ£ļŗż. ņØ┤ņÖĆ Ļ░ÖņØ┤ CNNņØä ņé¼ņÜ®ĒĢśļ®┤, ņØ╝ļ░śņŗĀĻ▓Įļ¦ØņØä ņØ┤ņÜ®ĒĢ£ ņØ┤ļ»Ėņ¦Ć ļČäņäØņŚÉņä£ ļŗ©ņĀÉņ£╝ļĪ£ ņ¦ĆņĀüļÉśņŚłļŹś ņØ┤ļ»Ėņ¦Ć ļé┤ņØś ņé¼ļ¼╝ņØś Ļ│ĄĻ░äņĀüņØĖ Ļ┤ĆĻ│äņŚÉ ļīĆĒĢ£ ņČöļĪĀĻ│╝ ļåÆņØĆ ĒĢ┤ņāüļÅä ņØ┤ļ»Ėņ¦ĆņØś ņ▓śļ”¼Ļ░Ć ĒÜ©Ļ│╝ņĀüņ£╝ļĪ£ ĒĢ┤Ļ▓░ļÉĀ ņłś ņ׳ļŗż.
ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ ņé¼ņÜ®ļÉ£ CNNņØś ņØĖĻ│ĄņŗĀĻ▓Įļ¦ØņØĆ ĻĖ░ļ│ĖņĀüņ£╝ļĪ£ Fig 2ņÖĆ Ļ░Öļŗż. ņ×ģļĀźņĖĄņŚÉņä£ļŖö ļ»ĖņäĖņĪ░ņ¦ü ņØ┤ļ»Ėņ¦ĆļŖö 512 ├Ś 512 ĒöĮņģĆņØä Ļ░Ćņ¦ĆĻ│Ā ņ׳ņ£╝ļ®░, Ļ░ü ĒöĮņģĆņØĆ RGB ņāēņāüņĀĢļ│┤ ņ▒äļäÉņØä Ļ░Ćņ¦ĆĻ│Ā ņ׳ļŗż. ņØĆļŗēņĖĄņØĆ ļäż Ļ░£ņØś CP Ļ│äņĖĄņØ┤ ņżæņ▓®ļÉśņ¢┤ ņ׳ņ£╝ļ®░, Ļ░ü CP Ļ│äņĖĄņØĆ Ļ░üĻ░üņØś ĒĢäĒä░ Ļ░£ņłśņÖĆ ļÅÖņłśņØś ņ▒äļäÉĻ│╝ ņżæĻ░äņĖĄ ņØ┤ļ»Ėņ¦Ćļź╝ Ļ░Ćņ¦ĆĻ│Ā ņ׳ļŗż. ņČ£ļĀź ņØ┤ļ»Ėņ¦ĆņØś Ēü¼ĻĖ░ļź╝ ņĪ░ņĀłĒĢśĻĖ░ ņ£äĒĢ£ Ēī©ļö®ņØĆ ņČöĻ░ĆĒĢśņ¦Ć ņĢŖņĢśļŗż. ĒĢ®ņä▒Ļ│▒ņŚÉņä£ņØś Ēī©ļö®ņØĆ ņØ┤ļ»Ėņ¦Ć ņŻ╝ņ£äņŚÉ 0ņ£╝ļĪ£ ņ▒äņøīņ¦ä ĒöĮņģĆņØä ņČöĻ░ĆĒĢśļŖö ņ×æņŚģņØĖļŹ░, ņČöņČ£ĒĢśĻ│Āņ×É ĒĢśļŖö ĒŖ╣ņĀĢ ņé¼ļ¼╝ņØ┤ ņØ┤ļ»Ėņ¦Ć ņżæņĢÖņŚÉ ņ£äņ╣śĒĢĀ ļĢīņŚÉļŖö Ēī©ļö®ņØä ņČöĻ░ĆĒĢ┤ļÅä ļ¼┤ļ░®ĒĢśļéś ņ×¼ļŻīņØś ļ»ĖņäĖņĪ░ņ¦üĻ│╝ Ļ░ÖņØ┤ Ēī©Ēä┤ņØś ĒśĢĒā£ļĪ£ ļéśĒāĆļé┤ļŖö ņØ┤ļ»Ėņ¦ĆņŚÉņä£ļŖö ĒŖ╣ņ¦Ģ ņČöņČ£ņŚÉ ļ░®ĒĢ┤ņÜöņåīļĪ£ ņ×æņÜ®ĒĢĀ Ļ░ĆļŖźņä▒ņØ┤ ņ׳ļŗż. ĒÆĆļ¦üņØĆ ņĄ£ļīĆĒÆĆļ¦üņØä ņé¼ņÜ®ĒĢśņśĆļŗż. ņØ┤Ēøä 2ņ░©ņøÉ ņØ┤ļ»Ėņ¦Ć ņĀĢļ│┤ļź╝ 1ņ░©ņøÉ ņłśņ╣ś ņĀĢļ│┤ļĪ£ ļ│ĆĒÖśĒĢśļŖö ĒÅēĒāäĒÖö(flatten) Ļ│╝ņĀĢņØä Ļ▒░ņ│É ļæÉ Ļ░£ņØś FC Ļ│äņĖĄņ£╝ļĪ£ ņŚ░Ļ▓░ļÉ£ļŗż. ņØ┤ļĢī FC Ļ│äņĖĄ ņé¼ņØ┤ņŚÉņä£ļŖö Ļ│╝ņĀüĒĢ®ņØä ļ░®ņ¦ĆĒĢśĻĖ░ ņ£äĒĢ£ ļō£ļĪŁņĢäņøā(dropout)ņØä 50% ņĀüņÜ®ĒĢśņśĆļŗż. ņČ£ļĀźņĖĄņØĆ ņ×ģļĀź ņØ┤ļ»Ėņ¦ĆņŚÉ ļö░ļØ╝ ĻĄ¼ņāüĒØæņŚ░ņŻ╝ņ▓ĀņØĖņ¦Ć ĒÜīņŻ╝ņ▓ĀņØĖņ¦Ć ļČäļźśĒĢśļŖö Ļ░ÆņØĖ 0 Ēś╣ņØĆ 1ņØ┤ ņČ£ļĀźļÉ£ļŗż. ĒÖ£ņä▒ĒÖöĒĢ©ņłśļŖö ņØĆļŗēņĖĄņŚÉ ļīĆĒĢ┤ņä£ ReLU (Rectified Linear Unit) ĒĢ©ņłśļź╝ ņé¼ņÜ®ĒĢśņśĆņ£╝ļ®░, ņĄ£ņóģņĀüņ£╝ļĪ£ ņØ┤ļ»Ėņ¦Ćļź╝ ļČäļźśĒĢśļŖö ņČ£ļĀźņĖĄņŚÉņä£ļŖö ņŗ£ĻĘĖļ¬©ņØ┤ļō£(sigmoid) ĒĢ©ņłśļź╝ ņé¼ņÜ®ĒĢśņśĆļŗż. ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ņØś ņØĆļŗēņĖĄņØś ņĖĄņłśņÖĆ ņ▒äļäÉņłś ļ░Å ļģĖļō£ņłś ļō▒ņØĆ Ļ░Ćņן ļŗ©ņł£ĒĢ£ ĒśĢĒā£ļĪ£ CNNņØ┤ ĻĄ¼ņä▒ļÉ©Ļ│╝ ļÅÖņŗ£ņŚÉ ņĄ£ņåīņØś ņåÉņŗżĻ│╝ ņĄ£ļīĆņØś ņĀĢĒÖĢļÅäļź╝ ņ£Āņ¦ĆĒĢśļÅäļĪØ ņŗ£Ē¢ēņ░®ņśżļź╝ Ļ▒░ņ│É Ļ▓░ņĀĢĒĢśņśĆļŗż. ĒĢ®ņä▒Ļ│▒ Ļ│äņĖĄņŚÉņä£ ņé¼ņÜ®ĒĢ£ ņŚ░ņé░ņŚÉ Ļ┤ĆĒĢ£ ņĪ░Ļ▒┤ņØĆ Table 1ņŚÉ ņĀĢļ”¼ĒĢśņśĆļŗż. ĒĢÖņŖĄņØĆ ņŚÉĒżĒü¼(epoch) ļŗ©ņ£äļĪ£ ņ¦äĒ¢ēļÉśļŖöļŹ░, 1 ņŚÉĒżĒü¼ļŖö ņżĆļ╣äļÉ£ ņ×ģļĀźļŹ░ņØ┤Ēä░ ņĀäņ▓┤ļź╝ ļ¬©ļæÉ ņé¼ņÜ®ĒĢśņŚ¼ ĒĢ£ ļ▓ł ĒøłļĀ©ļÉ£ ņāüĒā£ļź╝ ļ£╗ĒĢ£ļŗż. ņåÉņŗż(loss)ļĪ£ņä£ļŖö ņØ┤ņ¦ä Ēü¼ļĪ£ņŖżņŚöĒŖĖļĪ£Ēö╝(binary crossentropy)ļź╝ ņé¼ņÜ®ĒĢśņśĆņ£╝ļ®░, ņĄ£ņĀüĒÖö ļ░®ļ▓Ģņ£╝ļĪ£ļŖö RMSProp [17]ņØä ņé¼ņÜ®ĒĢśņśĆļŗż. ņ¦ĆĻĖłĻ╣īņ¦Ć ņäżļ¬ģĒĢ£ CNNņØĆ ĒīīņØ┤ņŹ¼(python)Ļ│╝ ņ╝ĆļØ╝ņŖż(keras)ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ĻĄ¼ĒśäĒĢśņśĆļŗż.
2.2 ļ»ĖņäĖņĪ░ņ¦ü ņØ┤ļ»Ėņ¦ĆņØś ņżĆļ╣ä
ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ ņé¼ņÜ®ļÉ£ ņŗ£ĒÄĖņØĆ ņāüņÜ® ĻĄ¼ņāüĒØæņŚ░ņŻ╝ņ▓Ā GCD450Ļ│╝ ĒÜīņŻ╝ņ▓Ā GC250ņØä ņé¼ņÜ®ĒĢśņśĆļŗż. ņØ┤ ļæÉ Ļ░Ćņ¦Ć ņŗ£ĒÄĖņØĆ ļ»ĖņäĖņĪ░ņ¦ü Ļ┤Ćņ░░ņØä ņ£äĒĢśņŚ¼ ņĪ░ņŚ░ļ¦łņÖĆ ļ»ĖņäĖņŚ░ļ¦łļź╝ Ļ▒░ņ│É ļéśņØ┤Ēāł 5% ņÜ®ņĢĪņ£╝ļĪ£ ļČĆņŗØĒĢśņśĆļŗż. ņØ┤ļĢī Ļ░ü ņŻ╝ņ▓ĀņØĆ ņØ┤ļ»Ėņ¦Ć ņł½ņ×ÉņØś ĒÖĢļ│┤ļź╝ ņ£äĒĢśņŚ¼ ļŗżņłśņØś ņŗ£ĒÄĖņØä ņé¼ņÜ®ĒĢśņśĆļŗż. Ļ┤æĒĢÖĒśäļ»ĖĻ▓ĮņØä ņØ┤ņÜ®ĒĢśņŚ¼ ļ»ĖņäĖņĪ░ņ¦ü ņØ┤ļ»Ėņ¦Ćļź╝ ņ¢╗ņŚłļŖöļŹ░, ņØ┤ļĢī Ēśäļ»ĖĻ▓ĮņØś ļ░░ņ£©ņØĆ ├Ś 50ņØ┤ņŚłņ£╝ļ®░, ļööņ¦ĆĒäĖ ņØ┤ļ»Ėņ¦ĆņØś Ēü¼ĻĖ░ļŖö 2048 ├Ś 1536 ĒöĮņģĆņØ┤ņŚłļŗż. ņØ┤ļĢī ņČĢņ▓Ö Ēæ£ņŗ£ ņŚåņØ┤ ņ┤¼ņśüĒĢśņśĆļŗż. ņØ┤ ņØ┤ļ»Ėņ¦Ćļź╝ 512 ├Ś 512 Ēü¼ĻĖ░ļĪ£ ļČäĒĢĀĒĢśļŖö ļ░®ņŗØņ£╝ļĪ£ ĒĢ£ ļ▓ł ņ┤¼ņśüņØä ĒåĄĒĢ┤ ļ»ĖņäĖņĪ░ņ¦ü ņØ┤ļ»Ėņ¦Ć 12Ļ░£ļź╝ ņ¢╗ņØä ņłś ņ׳ņŚłļŗż. ņØ┤ļ¤¼ĒĢ£ ļ░®ļ▓Ģņ£╝ļĪ£ ņ¢╗ņ¢┤ņ¦ä ņØ┤ļ»Ėņ¦Ć ņżæņŚÉņä£ ĻĄ¼ņāüĒØæņŚ░ņŻ╝ņ▓ĀĻ│╝ ĒÜīņŻ╝ņ▓Ā Ļ░üĻ░ü 3,000ņן ņØ┤ņāüņØś ņØ┤ļ»Ėņ¦Ćļź╝ ĒĢÖņŖĄĻ│╝ ĒģīņŖżĒŖĖ ļŹ░ņØ┤Ēä░ļĪ£ ĻĄ¼ņČĢĒĢśņśĆļŗż.
3. Ļ▓░Ļ│╝ ļ░Å Ļ│Āņ░░
3.1 ĒĢÖņŖĄņŚÉ ļīĆĒĢ£ ņåÉņŗż ļ░Å ņĀĢĒÖĢļÅä
ĻĄ¼ņāüĒØæņŚ░ņŻ╝ņ▓ĀĻ│╝ ĒÜīņŻ╝ņ▓ĀņØś ļ»ĖņäĖņĪ░ņ¦ü ņØ┤ļ»Ėņ¦Ć Ļ░üĻ░ü 3,000ņן ņżæ ļ¼┤ņ×æņ£äļĪ£ ņČöņČ£ĒĢ£ 60%ņØś ņØ┤ļ»Ėņ¦Ć(3,600 ņן)ļź╝ ĒøłļĀ©ņÜ®(training)ņ£╝ļĪ£ ņé¼ņÜ®ĒĢśņśĆņ£╝ļ®░, 30%ņØś ņØ┤ļ»Ėņ¦Ć(1,800 ņן)ļź╝ Ļ▓Ćņ”ØņÜ®(validation)ņ£╝ļĪ£ ņé¼ņÜ®ĒĢśņśĆļŗż. ļéśļ©Ėņ¦Ć 10%ņØś ņØ┤ļ»Ėņ¦ĆļŖö ĒģīņŖżĒŖĖ ņÜ®ļÅäļĪ£ ļé©Ļ▓╝ļŗż.
ĒĢÖņŖĄņØä 100 ņŚÉĒżĒü¼ ņłśĒ¢ēĒĢ£ Ļ▓░Ļ│╝ļź╝ Fig 3ņŚÉ ļéśĒāĆļé┤ņŚłļŗż.
ļæÉ ĻĘĖļלĒöäņØś xņČĢņØĆ ĒĢÖņŖĄ Ēܤņłśļź╝ ļéśĒāĆļé┤ļ®░, yņČĢņØĆ ĒøłļĀ©Ļ│╝ Ļ▓Ćņ”ØņØś ņåÉņŗżĻ│╝ ņĀĢĒÖĢļÅäļź╝ ļéśĒāĆļéĖļŗż. Ēīīļ×Ć ņŗżņäĀĻ│╝ ļ╣©Ļ░ä ņĀÉņØĆ Ļ░üĻ░ü ĒøłļĀ©ļŹ░ņØ┤Ēä░ņÖĆ Ļ▓Ćņ”ØļŹ░ņØ┤Ēä░ņŚÉ ļīĆĒĢ£ Ļ▓░Ļ│╝ļź╝ Ēæ£ņŗ£ĒĢ£ļŗż. ņåÉņŗżņØĆ ņØ┤ņ¦ä Ēü¼ļĪ£ņŖżņŚöĒŖĖļĪ£Ēö╝ļĪ£ ņé░ņČ£ĒĢśņśĆļŖöļŹ░, ņåÉņŗżņØ┤ ņ×æņØäņłśļĪØ ĒĢÖņŖĄņØ┤ ņל ņłśĒ¢ēļÉśņŚłļŗżĻ│Ā ĒīÉļŗ©ĒĢĀ ņłś ņ׳ļŗż. Fig 3(a)ņŚÉ ļéśĒāĆļéĖ ļ░öņÖĆ Ļ░ÖņØ┤ ĒøłļĀ©ļŹ░ņØ┤Ēä░ļŖö ĒĢÖņŖĄ ņ┤łĻĖ░ņŚÉ ĻĖēĻ▓®ĒĢśĻ▓ī Ļ░ÉņåīĒĢśļŗżĻ░Ć ļīĆļץ 20 ņŚÉĒżĒü¼ ņØ┤ĒøäņŚÉ ļ¦żņÜ░ ļé«ņØĆ ņłśņ╣śļĪ£ ņ£Āņ¦ĆļÉśļŖö Ļ▓āņØä Ļ┤Ćņ░░ĒĢĀ ņłś ņ׳ņŚłļŗż. ļ░śļ®┤ Ļ▓Ćņ”ØļŹ░ņØ┤Ēä░ņØś ņåÉņŗżņØĆ 20 ņŚÉĒżĒü¼Ļ╣īņ¦Ć Ļ░ÉņåīĒĢśļŗżĻ░Ć ļŗżņŗ£ ņ”ØĻ░ĆĒĢśņśĆļŗż. ņØ┤ļ¤¼ĒĢ£ ņ”ØĻ░ĆļŖö ĒøłļĀ©ļŹ░ņØ┤Ēä░ņØś Ļ│╝ņĀüĒĢ®(overfitting)ņ£╝ļĪ£ Ļ░äņŻ╝ļÉ£ļŗż. Fig 3(b)ļŖö ņ×ģļĀźļÉ£ ļŹ░ņØ┤Ēä░ņÖĆ ņČ£ļĀźļÉ£ Ļ▓░Ļ│╝ļ¼╝ņØś ņØ╝ņ╣śļÅäļź╝ ļéśĒāĆļé┤ļŖö ņĀĢĒÖĢļÅäņØ┤ļŗż. ĒĢÖņŖĄļŹ░ņØ┤Ēä░ļŖö ņåÉņŗżņŚÉņä£ ņśłņĖĪļÉ£ ļ░öņÖĆ ņ£Āņé¼ĒĢśĻ▓ī ĒĢÖņŖĄ ņ┤łĻĖ░ņŚÉ ĻĖēĻ▓®ĒĢśĻ▓ī ņāüņŖ╣ĒĢśņŚ¼ 20 ņŚÉĒżĒü¼ ņØ┤ĒøäņŚÉļŖö 100%ņŚÉ Ļ░ĆĻ╣īņÜ┤ ņĀĢĒÖĢļÅäļź╝ ļéśĒāĆļé┤ņŚłļŗż. ņåÉņŗżņŚÉņä£ Ļ│╝ņĀüĒĢ® ņ¢æņāüņØä ļéśĒāĆļéĖ Ļ▓Ćņ”ØļŹ░ņØ┤Ēä░ļŖö 20 ņŚÉĒżĒü¼ ņØ┤ĒøäņŚÉ Ļ│╝ņĀüĒĢ®ņŚÉļÅä ļČłĻĄ¼ĒĢśĻ│Ā 98% ņĀĢļÅäņØś ļåÆņØĆ ņĀĢĒÖĢļÅäļź╝ ņ£Āņ¦ĆĒĢśņśĆļŗż.
ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö 20 ņŚÉĒżĒü¼ ņØ┤ĒøäņØś ĒĢÖņŖĄņØ┤ Ļ│╝ņĀüĒĢ® ĒśäņāüņØä ļ│┤ņŚ¼, ņØ┤ ņØ┤ņāüņØś ĒĢÖņŖĄņØĆ ļ¼┤ņØśļ»ĖĒĢśļŗżĻ│Ā ĒīÉļŗ©ĒĢśņśĆļŗż. ĻĘĖļ¤¼ļ»ĆļĪ£ ņØ┤ĒøäņØś Ļ▓░Ļ│╝ņÖĆ Ļ│Āņ░░ņØĆ 20 ņŚÉĒżĒü¼ ĒĢÖņŖĄĻ▓░Ļ│╝ļĪ£ņä£ ņØ┤ļŻ©ņ¢┤ņĪīļŗż.
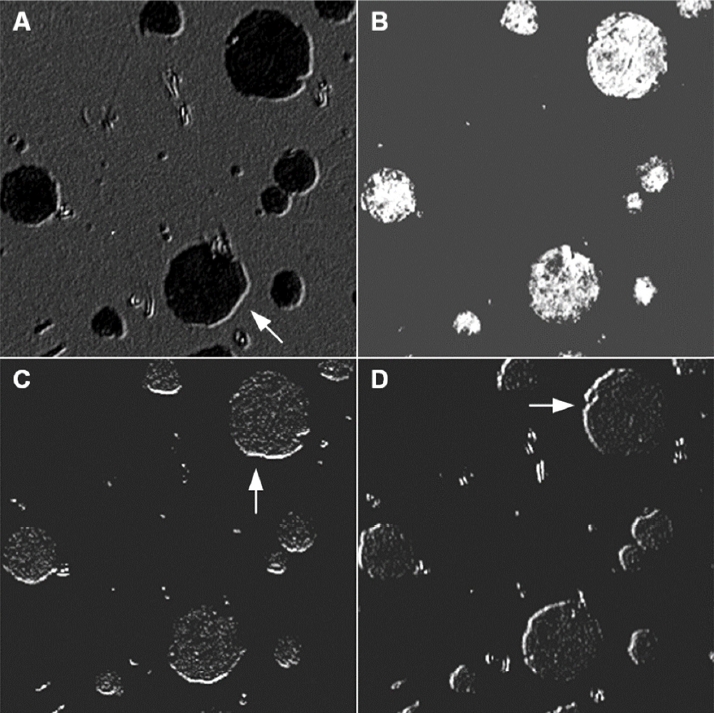
3.2 ņ┤łĻĖ░ ļ»ĖņäĖņĪ░ņ¦ü
ņżæĻ░äņĖĄ ņØ┤ļ»Ėņ¦Ćļź╝ ļČäņäØĒĢśĻĖ░ ņ£äĒĢ┤, ĒøłļĀ©ļŹ░ņØ┤Ēä░ņÖĆ Ļ▓Ćņ”ØļŹ░ņØ┤Ēä░ņŚÉ ĒżĒĢ©ļÉśņ¦Ć ņĢŖņØĆ ĻĄ¼ņāüĒØæņŚ░ņŻ╝ņ▓ĀĻ│╝ ĒÜīņŻ╝ņ▓ĀņØś ļ»ĖņäĖņĪ░ņ¦ü ņØ┤ļ»Ėņ¦Ć(512 ├Ś 512)ļź╝ ĒĢ£ ņןņö® ņżĆļ╣äĒĢśņśĆļŗż. ņØ┤ļĢī ņØ┤ļ»Ėņ¦ĆļŖö Fig 4ņŚÉ ļéśĒāĆļé┤ņŚłļŗż. Ļ░ü ņØ┤ļ»Ėņ¦ĆļŖö ĒØæļ░▒ņ£╝ļĪ£ ļ│┤ņØ┤ņ¦Ćļ¦ī RGBņØś ņāēņāüņĀĢļ│┤ļź╝ Ļ░Ćņ¦ĆĻ│Ā ņ׳ļŖö 3Ļ░£ņØś ņ▒äļäÉņØä Ļ░Ćņ¦ä ļŹ░ņØ┤Ēä░ļĪ£ Ļ░äņŻ╝ĒĢĀ ņłś ņ׳ļŗż. ļŗ©, ĒØæļ░▒ņ£╝ļĪ£ ļ│┤ņØ┤ļŖö Ļ▓āņ£╝ļĪ£ ļ│┤ņĢä RGBņØś Ļ░ü ņłśņ╣śļŖö ņØ╝ņĀĢĒĢśļŗżĻ│Ā ĒīÉļŗ©ĒĢĀ ņłś ņ׳ļŗż. ĻĄ¼ņāüĒØæņŚ░ņŻ╝ņ▓ĀņŚÉļŖö Fig 4(a)ņŚÉņä£ ļ│┤ļŖö ļ░öņÖĆ Ļ░ÖņØ┤ Ēü¼Ļ│Ā ņ×æņØĆ ĻĄ¼ņāüĒØæņŚ░ņĪ░ņ¦üņØ┤ ĒÄśļØ╝ņØ┤ĒŖĖ ĻĖ░ņ¦Ć ņāüņŚÉ ļČäĒżļÉśņ¢┤ ņ׳ļŗż. ĒÜīņŻ╝ņ▓ĀņŚÉļŖö ĒÄäļØ╝ņØ┤ĒŖĖ ĻĖ░ņ¦Ć ņāüņŚÉ ĻĄĮņ¢┤ņ¦ä ĒśĢĒā£ņØś ĒÄĖņāüĒØæņŚ░ņĪ░ņ¦üņØ┤ ļČäĒżļÉśņ¢┤ ņ׳ļŗż. ņé¼ņ¦äņŚÉņä£ ļ│┤ļŖö ļ░öņÖĆ Ļ░ÖņØ┤ ĻĄ¼ņāüĒØæņŚ░ņŻ╝ņ▓ĀĻ│╝ ĒÜīņŻ╝ņ▓ĀņØś ļ»ĖņäĖņĪ░ņ¦üņØĆ ņ£ĪņĢłņ£╝ļĪ£ļÅä ņēĮĻ▓ī ĒīÉļ│äĒĢĀ ņłś ņ׳ļŗż. ņ¦üĻ┤ĆņĀüņ£╝ļĪ£ ĒīÉļŗ©ĒĢśļ®┤, ĻĄ¼ņāüĒØæņŚ░ņŻ╝ņ▓ĀņØĆ ļ»ĖņäĖņĪ░ņ¦ü ņØ┤ļ»Ėņ¦ĆņāüņØś ņøÉĒśĢ ĻĄ¼ņāüĒØæņŚ░ņĪ░ņ¦üņ£╝ļĪ£ ĻĄ¼ņāüĒØæņŚ░ņŻ╝ņ▓Āņ×äņØä ĒīÉļŗ©ĒĢĀ ņłś ņ׳Ļ│Ā, ĒÜīņŻ╝ņ▓ĀņŚÉņä£ļŖö ĒÄĖņāüĒØæņŚ░ņĪ░ņ¦üņØä ņØĖņ¦ĆĒĢ©ņ£╝ļĪ£ņŹ© ĒÜīņŻ╝ņ▓Āņ×äņØä ĒīÉļŗ©ĒĢĀ ņłś ņ׳ļŗż. ĻĖ░ņ¦ĆņāüņØ┤ ĒÄäļØ╝ņØ┤ĒŖĖ Ēś╣ņØĆ ĒÄśļØ╝ņØ┤ĒŖĖļĪ£ ņØ┤ļŻ©ņ¢┤ņĀĖ ņ׳ļŖö Ļ▓āņØä ĒīÉļ│äĒĢśĻĖ░ņŚÉļŖö ņ¢┤ļĀżņÜ░ļ®░, ļ│┤ļŗż ņä¼ņäĖĒĢ£ ņŚÉņ╣ŁĻ│╝ Ļ│ĀĒĢ┤ņāüļÅä ņØ┤ļ»Ėņ¦Ćļź╝ ĒåĄĒĢ┤ņä£ļŖö Ļ░ĆļŖźĒĢĀ Ļ▓āņØ┤ļŗż.
3.3 ĻĄ¼ņāüĒØæņŚ░ņŻ╝ņ▓ĀņŚÉņä£ņØś ņżæĻ░äņĖĄ ņØ┤ļ»Ėņ¦Ć ļČäņäØ
ļ│ĖņŚ░ĻĄ¼ņŚÉņä£ļŖö, CNNņŚÉņä£ ņ£äņØś ļæÉ Ļ░Ćņ¦Ć ņóģļźśņØś ļ»ĖņäĖņĪ░ņ¦üņØä ļČäļ│äĒĢ©ņŚÉ ņ׳ņ¢┤ņä£ ņ¢┤ļ¢ż ņżæĻ░ä Ļ│╝ņĀĢņØä Ļ▒░ņ╣śļŖöņ¦Ć ņĢīĻĖ░ ņ£äĒĢśņŚ¼, Fig 4ņØś ņØ┤ļ»Ėņ¦Ćļź╝ ņ£äņŚÉņä£ ĒĢÖņŖĄļÉ£ ĻĖ░Ļ│äĒĢÖņŖĄ ņŗ£ņŖżĒģ£ņŚÉ ņ×ģļĀźĒĢśņśĆļŗż. ļ©╝ņĀĆ ĻĄ¼ņāüĒØæņŚ░ņŻ╝ņ▓ĀņØś ļ»ĖņäĖņĪ░ņ¦ü ņØ┤ļ»Ėņ¦Ć Fig 4(a)ļź╝ ņ×ģļĀźĒĢśņśĆĻ│Ā, ņØ┤ņŚÉ ļīĆĒĢ┤ņä£ Ļ│Āņ░░ĒĢśĻ│Āņ×É ĒĢ£ļŗż.
ņ▓½ļ▓łņ¦Ė ĒĢ®ņä▒Ļ│▒-ĒÖ£ņä▒ĒÖö-ĒÆĆļ¦üņØś ļ│ĄĒĢ®Ļ│äņĖĄ(CP1)ņØä ĒåĄĻ│╝ĒĢ£ ĒŖ╣ņä▒ļ¦Ą(feature map)ņŚÉņä£ļŖö ņ┤Ø 8Ļ░£ņØś ņżæĻ░äņĖĄ ņØ┤ļ»Ėņ¦ĆĻ░Ć ņāØņä▒ļÉśņŚłņ£╝ļ®░ ņØ┤ļŖö ĒĢ┤ļŗ╣ Ļ│äņĖĄņØś ļŹ░ņØ┤Ēä░ļź╝ ĒśĢņä▒ĒĢśĻĖ░ ņ£äĒĢśņŚ¼ 8Ļ░£ņØś ĒĢäĒä░Ļ░Ć ņé¼ņÜ®ļÉśņŚłļŗżļŖö Ļ▓āņØä ļ£╗ĒĢ£ļŗż. 8Ļ░£ņØś ņØ┤ļ»Ėņ¦Ć ņżæ ņØ┤ņżæ 4Ļ░£ļź╝ ņČöņČ£ĒĢśņŚ¼ Fig 5ņŚÉ ļéśĒāĆļé┤ņŚłļŗż. ņżæĻ░äņĖĄņØś ņØ┤ļ»Ėņ¦ĆļŖö ĒÜīņāēĒåżņØś ņØ┤ļ»Ėņ¦ĆļĪ£ ļéśĒāĆļé┤ņ¦Ć ļ¬╗ĒĢĀ ņłś ņ׳ļŗż. ņ”ē ĒÜīņāēĒåż ņØ┤ļ»Ėņ¦ĆļŖö Ļ░ü ĒöĮņģĆņØś ņłśņ╣śĻ░Ć 0(ĒØæņāē) ~ 255(ļ░▒ņāē)ņØś Ļ░ÆņØä Ļ░¢Ļ▓ī ļÉśļŖöļŹ░, ĒĢ®ņä▒Ļ│▒ Ļ│╝ņĀĢņŚÉņä£ļŖö ņØ┤ ļ▓öņ£äļź╝ ļ▓Śņ¢┤ļéĀ Ļ░ĆļŖźņä▒ņØ┤ ņ׳ļŗżļŖö ļ£╗ņØ┤ļŗż. ņØ┤ ļ¼ĖņĀ£ļź╝ ĒĢ┤Ļ▓░ĒÖöĒĢśĻĖ░ ņ£äĒĢśņŚ¼ Ļ░ü ĒöĮņģĆņØś ņłśņ╣śļŖö ļ¬©ļōĀ ĒöĮņģĆņØś ĒÅēĻĘĀĻ░ÆĻ│╝ Ēæ£ņżĆ ĒÄĖņ░©ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ Ēæ£ņżĆĒÖö(standardization)ĒĢ£ Ēøä 0 ~ 255ņØś Ļ░ÆņØä Ļ░¢ļÅäļĪØ ļ▓öņ£äļź╝ ņĪ░ņĀĢĒĢśņśĆļŗż. ņŗżņĀ£ ņČ£ļĀźļÉ£ ņØ┤ļ»Ėņ¦ĆļŖö ņé¼ņ¦äņŚÉ ļéśĒāĆļé£ Ļ▓āļ│┤ļŗż ļŹöņÜ▒ ņ¢┤ļæÉņøĀļŖöļŹ░, ĒÄĖņØśļź╝ ņ£äĒĢśņŚ¼ ņØ┤ļ»Ėņ¦Ćļź╝ ņĢĮĻ░ä ļ░ØĻ▓ī ļ│┤ņĀĢĒĢśņśĆļŗż. ĒĢ®ņä▒Ļ│▒Ļ│╝ ĒÖ£ņä▒ĒÖö, Ēī©ļö® Ļ│╝ņĀĢņØä ĒåĄĻ│╝ĒĢśļ®┤ņä£ ņØ┤ļ»Ėņ¦ĆņØś Ēü¼ĻĖ░ļŖö ņĄ£ņ┤ł 512 ├Ś 512 ĒöĮņģĆņŚÉņä£ 255 ├Ś 255 ĒöĮņģĆļĪ£ ņČĢņåīļÉśņŚłļŗż. ņØ┤ ņØ┤ļ»Ėņ¦ĆļōżņØĆ CNN ĒøłļĀ©Ļ│╝ņĀĢņØä ĒåĄĒĢśņŚ¼ ņĄ£ņĀüĒÖöļÉ£ ĒĢäĒä░(3 ├Ś 3 ĒöĮņģĆ)ņÖĆ ļ░śņØæĒĢśņŚ¼ ņāØņä▒ļÉ£ ņØ┤ļ»Ėņ¦ĆļōżņØ┤ļŗż. ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ ĒĢäĒä░ņØś ņé¼ņØ┤ņ”łĻ░Ć ņ×æņØĆ Ļ┤ĆĻ│äļĪ£ ĒĢäĒä░ņØś ĒśĢĒā£ļŖö ĒīīņĢģĒĢśņ¦Ć ļ¬╗Ē¢łņ¦Ćļ¦ī, ĻĘĖ ņŚŁĒĢĀņŚÉ ļīĆĒĢ┤ņä£ļŖö ĻĘĖ ĒÜ©Ļ│╝ļź╝ ņ¦Éņ×æĒĢĀ ņłś ņ׳ļŗż. Fig 5ņŚÉņä£ AļŖö ņ×ģļĀź ļŹ░ņØ┤Ēä░ Fig 4(a)ņØś ļ¬ģņĢöņØä Ļ▒░ņØś ĻĘĖļīĆļĪ£ ņ£Āņ¦ĆĒĢśĻ│Ā ņ׳ņ£╝ļéś, BņŚÉņä£ļŖö ļ¬ģņĢöņØ┤ ļ░śņĀäļÉśņ¢┤ ņ׳ļŖö Ļ▓āņØä ĒÖĢņØĖĒĢśņśĆļŗż. CņÖĆ DņŚÉņä£ļŖö ĻĖ░ņ¦ĆņāüĻ│╝ ĻĄ¼ņāüĒØæņŚ░ņāüņØś ļ¬ģņĢöĻĄ¼ļ│äņØ┤ ļ¼┤ņŗ£ļÉśņ¢┤ ņ׳ļŖö Ļ▓āņØä ņĢī ņłś ņ׳ļŗż. AņØś Ļ▓ĮņÜ░ ņ×ģļĀźņØ┤ļ»Ėņ¦ĆņØś ļ¬ģņĢöņØä ņ£Āņ¦ĆĒĢśņ¦Ćļ¦ī, ĒÖöņé┤Ēæ£ļĪ£ Ēæ£ņŗ£ĒĢ£ ļ░öņÖĆ Ļ░ÖņØ┤ ĻĄ¼ņāüĒØæņŚ░ņāüņØś 5ņŗ£ ļ░®Ē¢ź ņ£żĻ│ĮņäĀņØ┤ ļ░ØņØĆ ņāēņ£╝ļĪ£ Ļ░ĢņĪ░ļÉśņ¢┤ ņ׳ļŗż. ļ¬ģņĢöņØ┤ ļ░śņĀäļÉ£ BņŚÉņä£ļŖö ņØ┤ļ¤¼ĒĢ£ ĒśäņāüņØä ņØĖņ¦ĆĒĢśĻĖ░ ņ¢┤ļĀżņøĀņ£╝ļéś, CņÖĆ DņŚÉņä£ļŖö ĒÖöņé┤Ēæ£ļĪ£ Ēæ£ņŗ£ĒĢ£ ļ░öņÖĆ Ļ░ÖņØ┤ Ļ░üĻ░ü 6ņŗ£ ļ░®Ē¢źĻ│╝ 10ņŗ£ ļ░®Ē¢źņ£╝ļĪ£ ĒģīļæÉļ”¼Ļ░Ć ļ░ØņØĆ ņāēņ£╝ļĪ£ Ļ░ĢņĪ░ļÉśņ¢┤ ņ׳ļŗż. ņØ┤ļ¤¼ĒĢ£ Ļ▓░Ļ│╝ļĪ£ ļ»ĖļŻ©ņ¢┤ ļ│╝ ļĢī, AļŖö ņ×ģļĀź ņØ┤ļ»Ėņ¦ĆņÖĆ ĒĢäĒä░ņÖĆņØś ĒĢ®ņä▒Ļ│▒ņØä ĒåĄĒĢśņŚ¼ ņøÉļל ļ¬ģņĢö ņāüĒā£ņŚÉņä£ Ļ│ĪļźĀņŚÉ ļö░ļźĖ ņ£żĻ│ĮņäĀņØä ņČöņČ£ĒĢśļŖö Ļ▓āņ£╝ļĪ£ ĒīÉļŗ©ļÉ£ļŗż. BņØś Ļ▓ĮņÜ░ņŚÉļŖö ļ¬ģņĢö ļ░śņĀä ĒÜ©Ļ│╝ļĪ£ ņøÉļל ņØ┤ļ»Ėņ¦ĆņŚÉņä£ ņ░ŠņØä ņłś ņŚåļŖö ņØ┤ļ»Ėņ¦Ć Ļ▓ĆņČ£ņØä ņŗ£ļÅäĒĢ£ Ļ▓āņ£╝ļĪ£ ņśłņāüļÉ£ļŗż. CņÖĆ DņØś Ļ▓ĮņÜ░ņŚÉļŖö ĻĖ░ņ¦ĆņāüĻ│╝ ĻĄ¼ņāüĒØæņŚ░ņāüņØś ļ¬ģņĢöļ│┤ļŗżļŖö ņ£żĻ│ĮņäĀ ņČöņČ£ņŚÉ ņ┤łņĀÉņØä ļ¦×ņČöņŚłļŗż.
Fig 6ņØĆ ļæÉļ▓łņ¦Ė ĒĢ®ņä▒Ļ│▒Ļ│äņĖĄ(CP2)ņØä ĒåĄĻ│╝ĒĢ£ ĒøäņØś ĒŖ╣ņĀĢļ¦Ąņ£╝ļĪ£ļČĆĒä░ Ļ░ü ņ▒äļäÉņØś ļŹ░ņØ┤Ēä░ļź╝ ņØ┤ļ»Ėņ¦ĆļĪ£ ļéśĒāĆļéĖ Ļ▓āņØ┤ļŗż. CP2ņŚÉņä£ļŖö ņ┤Ø 16Ļ░£ņØś ņ▒äļäÉņØä ņé¼ņÜ®ĒĢśļ»ĆļĪ£ 16Ļ░£ņØś ņżæĻ░äņĖĄ ņØ┤ļ»Ėņ¦ĆĻ░Ć ņāØņä▒ļÉśņŚłņ£╝ļ®░ ņØ┤ņżæ 6Ļ░£ļź╝ ĻĘĖļ”╝ņŚÉ ļéśĒāĆļé┤ņŚłļŗż. CP1ņØĆ ĒĢ£ Ļ░£ņØś 3ņ▒äļäÉ ņ×ģļĀź ļŹ░ņØ┤Ēä░ ņØ┤ļ»Ėņ¦Ćļź╝ Ļ░¢ļŖö ļ░śļ®┤, CP2ņŚÉņä£ļŖö ņØ┤ņĀä Ļ│äņĖĄņŚÉņä£ ĒśĢņä▒ļÉ£ 8Ļ░£ņØś ņØ┤ļ»Ėņ¦Ćļź╝ 8ņ▒äļäÉ ņ×ģļĀź ļŹ░ņØ┤Ēä░ļĪ£ ņ▓śļ”¼ĒĢśņśĆļŗż. Ļ▓░Ļ│╝ņĀüņ£╝ļĪ£ CP2ļź╝ ĒåĄĻ│╝ĒĢśļ®┤ņä£ ņØ┤ļ»Ėņ¦ĆņØś Ēü¼ĻĖ░ļŖö ņ×ģļĀźļŹ░ņØ┤Ēä░ņØś 255 ├Ś 255 ĒöĮņģĆņŚÉņä£ 126 ├Ś 126 ĒöĮņģĆļĪ£ ņČĢņåīļÉśņŚłļŗż. CP2ņŚÉņä£ņØś ņØ┤ļ»Ėņ¦ĆļŖö CP1ņŚÉņä£ņÖĆ ņ£Āņé¼ĒĢśĻ▓ī ļ¬ģņĢöņØś ļ│ĆĒÖöļź╝ ļéśĒāĆļéĖ ņØ┤ļ»Ėņ¦Ćļōż(BņÖĆ D, F)ņØ┤ ļ░£Ļ▓¼ļÉśņŚłĻ│Ā ņ£żĻ│ĮņäĀ(AņÖĆ B, C, E, F)ņØ┤ ņŚ¼ņĀäĒ׳ Ļ░ĢņĪ░ļÉśņ¢┤ ņ׳ļŗż. ļŗ©ņ¦Ć ņ£żĻ│ĮņäĀ ļČĆļČäņØś Ļ░ĢņĪ░ļŖö CP1 ļ│┤ļŗż ļŹöņÜ▒ ņśüņŚŁņØ┤ ĒÖĢļīĆļÉśĻ│Ā ļåÆņØĆ ļ¬ģņĢöļ╣äļź╝ ļéśĒāĆļé┤ļŖö Ļ▓āņØä ņĢī ņłś ņ׳ļŗż.
ņØ┤ Ļ▓ĮĒ¢źņØĆ ņØ┤ļ»Ėņ¦ĆņØś Ēü¼ĻĖ░Ļ░Ć 62 ├Ś 62 ĒöĮņģĆļĪ£ ņČĢņåīļÉ£ CP3 ņ¦üĒøäņØś ņØ┤ļ»Ėņ¦ĆņŚÉņä£ļÅä ļ░£Ļ▓¼ļÉ£ļŗż. ļ¬ģņĢöļ╣äņÖĆ ĒģīļæÉļ”¼ņØś Ļ░ĢņĪ░Ļ░Ć ļ░śļ│ĄļÉśļŗżĻ░Ć ņĄ£ņóģņĀüņ£╝ļĪ£ 30 ├Ś 30 ĒöĮņģĆļĪ£ ņČĢņåīļÉ£ CP4 ņ¦üĒøäņØś ņØ┤ļ»Ėņ¦ĆļŖö Fig 7ņŚÉ ļéśĒāĆļé┤ņŚłļŗż. CP4ņŚÉņä£ļŖö ņ┤Ø 32Ļ░£ņØś ņ▒äļäÉņØä Ļ░Ćņ¦ä ĒŖ╣ņä▒ļ¦Ąņ£╝ļĪ£ļČĆĒä░ 32Ļ░£ņØś ņżæĻ░äņĖĄ ņØ┤ļ»Ėņ¦ĆĻ░Ć ņāØņä▒ļÉśņŚłļŗż. ņØ┤ņżæ 6Ļ░£ņØś ņØ┤ļ»Ėņ¦Ćļź╝ ĻĘĖļ”╝ņŚÉ ļéśĒāĆļéĖ Ļ▓āņØ┤ļŗż. CP4ņŚÉņä£ ņČ£ļĀźļÉ£ ņØ┤ļ»Ėņ¦ĆļōżņØĆ ļŹö ņØ┤ņāü ĒĢ®ņä▒Ļ│▒ Ļ│äņĖĄņØä Ļ▒░ņ╣śņ¦Ć ņĢŖĻ│Ā, ĒÅēĒāäĒÖö Ļ░ĆņĀĢņØä Ļ▒░ņ│É ņÖäņĀäĻ▓░ĒĢ® Ļ│äņĖĄņ£╝ļĪ£ ņŚ░Ļ▓░ļÉ£ļŗż. Fig 7ņÖĆ ņĄ£ņ┤łņØś ņ×ģļĀź ļŹ░ņØ┤Ēä░ņØĖ Fig 4ļź╝ ļ╣äĻĄÉĒĢ┤ļ│┤ļ®┤, ļ╣äļĪØ ņØ┤ļ»Ėņ¦ĆņØś Ēü¼ĻĖ░Ļ░Ć ļ¦ÄņØ┤ ņČĢņåīļÉśĻĖ┤ Ē¢łņ¦Ćļ¦ī, ĻĄ¼ņāüĒØæņŚ░ņāüņØś ņ£äņ╣śļéś ĒśĢĒā£ ļō▒ņØś ĒŖ╣ņä▒ļōżņØ┤ Ļ│ĀņŖżļ×ĆĒ׳ ņČöņČ£ļÉśņ¢┤ ņ׳ļŖö Ļ▓āņØä ĒÖĢņØĖĒĢĀ ņłś ņ׳ļŗż. Fig 7ņØś Ļ░ü ņØ┤ļ»Ėņ¦ĆļōżņØĆ ļŗ©ņł£ĒÖöļÉ£ ĒśĢĒā£ņØś ļ»ĖņäĖņĪ░ņ¦üņØś ĒŖ╣ņä▒ņØä ņĀ£Ļ░üĻĖ░ ļ│┤ņ£ĀĒĢśĻ│Ā ņ׳ļŗż. ņĀäņ▓┤ņĀüņØĖ ĒØÉļ”äņ£╝ļĪ£ ĒīÉļŗ©ĒĢ┤ ļ│╝ ļĢī CNNņŚÉņä£ļŖö ĻĄ¼ņāüĒØæņŚ░ņāüņØś ĒśĢĒā£ņŚÉ ļīĆĒĢ£ ļČäņäØņØ┤ ņŻ╝ļĪ£ ņØ┤ļŻ©ņ¢┤ņ¦äļŗżļŖö Ļ▓āņ£╝ļĪ£ Ļ▓░ļĪĀņ¦ĆņØä ņłś ņ׳ļŗż.
3.4 ĒÜīņŻ╝ņ▓ĀņŚÉņä£ņØś ņżæĻ░äņĖĄ ņØ┤ļ»Ėņ¦Ć ļČäņäØ
CNNņŚÉ ņØśĒĢ£ ĒÜīņŻ╝ņ▓Ā ļ»ĖņäĖņĪ░ņ¦ü ņØ┤ļ»Ėņ¦ĆņØś ņŗØļ│äņŚÉ ļīĆĒĢ£ ņżæĻ░äņĖĄ ņØ┤ļ»Ėņ¦ĆļŖö Fig 8ņŚÉ ļéśĒāĆļé┤ņŚłļŗż. ĻĄ¼ņāüĒØæņŚ░ņŻ╝ņ▓Ā ļ»ĖņäĖņĪ░ņ¦üņŚÉ ļīĆĒĢ£ ļČäņäØņØĆ ņĀä ņĀłņŚÉņä£ ļ╣äĻĄÉņĀü ņ×ÉņäĖĒĢśĻ▓ī ļģ╝ņØśĒĢśņśĆņ£╝ļ»ĆļĪ£, ņØ┤ ĻĘĖļ”╝ņŚÉņä£ļŖö CP1Ļ│╝ ņĄ£ņóģņĀüņØĖ CP4ņŚÉņä£ņØś ņØ┤ļ»Ėņ¦Ćļ¦īņØä ļéśĒāĆļé┤ņŚłļŗż. CP1 ņ¦üĒøäņØś ņØ┤ļ»Ėņ¦ĆņØĖ Fig 8(a)ņŚÉņä£ļŖö ĻĄ¼ņāüĒØæņŚ░ņŻ╝ņ▓ĀņØś ņØ┤ļ»Ėņ¦ĆņÖĆ ļ╣äņŖĘĒĢśĻ▓ī ļ»ĖņäĖņĪ░ņ¦ü ņØ┤ļ»Ėņ¦ĆņØś ļ¬ģņĢö ļ│ĆĻ▓ĮĻ│╝ ĒĢ©Ļ╗ś, ĒÄĖņāüĒØæņŚ░ņĪ░ņ¦üņØś ĒģīļæÉļ”¼ņŚÉ ļīĆĒĢ£ ļČäņäØņØ┤ ņØ┤ļŻ©ņ¢┤ņ¦ÉņØä ņĢī ņłś ņ׳ļŗż. ņŻ╝ņØśĒĢ┤ņĢ╝ĒĢĀ ņĀÉņØĆ ņØ┤ ņØ┤ļ»Ėņ¦ĆļŖö ĻĄ¼ņāüĒØæņŚ░ņŻ╝ņ▓ĀņØś ņØ┤ļ»Ėņ¦Ć ļČäņäØņŗ£ ņé¼ņÜ®ļÉśņŚłļŹś ĒĢäĒä░Ļ░Ć ļÅÖņØ╝ĒĢśĻ▓ī ņĀüņÜ®ļÉśņŚłļŗżļŖö Ļ▓āņØ┤ļŗż. ņ”ē, ĻĄ¼ņāüĒØæņŚ░ņŻ╝ņ▓ĀĻ│╝ ĒÜīņŻ╝ņ▓ĀņØś ļ»ĖņäĖņĪ░ņ¦ü ņØ┤ļ»Ėņ¦Ćļź╝ ļÅÖņŗ£ņŚÉ ĒĢÖņŖĄĒĢśņśĆĻĖ░ ļĢīļ¼ĖņŚÉ ļ¦łņ¦Ćļ¦ēņ£╝ļĪ£ ņĄ£ņĀüĒÖöļÉśņŚłļŹś ĒĢäĒä░Ļ░Ć ņĀüņÜ®ļÉ£ Ļ▓āņØ┤ļŗż. ļŗ©ņł£ĒĢ£ ņøÉĒśĢņŚÉ Ļ░ĆĻ╣īņÜ┤ ĻĄ¼ņāüĒØæņŚ░ņĪ░ņ¦üņØś ņżæĻ░äņĖĄ ņØ┤ļ»Ėņ¦ĆņŚÉņä£ļŖö ņ£żĻ│ĮņäĀ ņØĖņŗØņØś ļ░®Ē¢źņØä ņēĮĻ▓ī ĒīīņĢģĒĢĀ ņłś ņ׳ņŚłņ£╝ļéś, ĒÜīņŻ╝ņ▓ĀņØś ĒÄĖņāüĒØæņŚ░ņĪ░ņ¦üņØĆ ņŚ¼ļ¤¼ ļ░®Ē¢źņ£╝ļĪ£ ĻĄ┤Ļ│ĪļÉśņ¢┤ ņ׳ņ¢┤ ņ£żĻ│ĮņäĀ ņØĖņŗØņØś ļ░®Ē¢źņØś ĒīīņĢģņØ┤ ņēĮņ¦Ć ņĢŖļŗż.
ļäż ļ▓łņØś ĒĢ®ņä▒Ļ│▒ Ļ│äņĖĄņØä ĒåĄĻ│╝ĒĢśņŚ¼ ņāØņä▒ļÉ£ ņĄ£ņóģņĀüņØĖ ņżæĻ░äņĖĄ ņØ┤ļ»Ėņ¦ĆņØĖ Fig 8(b)ļź╝ ņé┤ĒÄ┤ļ│┤ļ®┤, ņØ┤ļ»Ėņ¦ĆņØś ĒÖöņåīņłśĻ░Ć Ēü¼Ļ▓ī ņżäņ¢┤ļōżņ¢┤ ĻĄ¼ņāüĒØæņŚ░ņĪ░ņ¦üĻ│╝ļŖö ļŗ¼ļ”¼ ĒÄĖņāüĒØæņŚ░ņĪ░ņ¦üņØä ĒīīņĢģĒĢśĻĖ░ļŖö ņ¢┤ļĀĄļŗż. ļŗ©ņ¦Ć, ņ┤łĻĖ░ ņ×ģļĀź ņØ┤ļ»Ėņ¦Ć Fig 4(b)ņÖĆ ļ╣äĻĄÉĒĢ┤ļ│╝ ļĢī ĒÄĖņāüĒØæņŚ░ņĪ░ņ¦üņØś ņ£äņ╣śņÖĆ ĒśĢĒā£ļź╝ ļīĆļץņĀüņ£╝ļĪ£ ņ¦Éņ×æĒĢĀ ņłś ņ׳ņØä ļ┐ÉņØ┤ņŚłļŗż. ĻĘĖļ¤¼ļéś, ņØ┤ļ¤¼ĒĢ£ ņØ┤ļ»Ėņ¦ĆļÅä Ļ░ü ĒÄĖņāüĒØæņŚ░ņĪ░ņ¦üņØś ĒŖ╣ņä▒ņØä ņל ņČöņČ£ĒĢśņŚ¼ ļéśĒāĆļéĖ Ļ▓āņØ┤ĻĖ░ ļĢīļ¼ĖņŚÉ CNNņŚÉņä£ņØś ņØ┤ļ»Ėņ¦Ć ļČäļźśņŚÉļŖö Ēü░ ņ¦ĆņןņØ┤ ņŚåņØä Ļ▓āņØ┤ļŗż.
ņØ┤ņāüņØś ņżæĻ░äņĖĄ ņØ┤ļ»Ėņ¦Ć ļČäņäØņ£╝ļĪ£ ļ»ĖļŻ©ņ¢┤ ļ│┤ņĢä, ņŻ╝ņ▓Ā ļ»ĖņäĖņĪ░ņ¦ü ņØ┤ļ»Ėņ¦ĆņØś ļČäņäØņŚÉņä£ļŖö ņŻ╝ļĪ£ ĻĄ¼ņāüĒØæņŚ░ņāüĻ│╝ ĒÄĖņāüĒØæņŚ░ņāüņØś ĒśĢĒā£ļź╝ ņżæņŗ¼ņ£╝ļĪ£ ņŻ╝ņ▓ĀņØś ņóģļźśļź╝ ĒīīņĢģĒĢĀ ņłś ņ׳ļŗżĻ│Ā ĒīÉļŗ©ļÉ£ļŗż. Ļ│äņĖĄņØ┤ ņŗ¼ĒÖöļÉĀņłśļĪØ ĒØæņŚ░ņāüņØś ĒśĢĒā£ņŚÉņä£ Ļ░Ćņן ĒŖ╣ņ¦ĢņĀüņØĖ Ļ▓āņØä ņČöņČ£ĒĢśņŚ¼ ņĀäņ▓┤ņĀüņØĖ ņØ┤ļ»Ėņ¦Ćļź╝ ļŗ©ņł£ĒÖöĒĢśĻ│Ā ņČĢņåīĒĢśļŖö Ļ▓āņ£╝ļĪ£ ĒīÉļŗ©ļÉ£ļŗż. CNNņ£╝ļĪ£ ļ│ĆĒÖśļÉ£ ņØ┤ļ»Ėņ¦Ćļź╝ ņé¼ļ×īņØ┤ ļ┤żņØäļĢī ĻĘĖ ņØśļ»Ėļź╝ ņ¦üņĀæ ĒīīņĢģĒĢśĻĖ░ļŖö Ēלļōżņ¦Ćļ¦ī, ĻĖ░Ļ│äĒĢÖņŖĄņØś ņ×ģņןņ£╝ļĪ£ ļ┤żņØä ļĢīņŚÉļŖö ņ╗┤Ēō©Ēä░Ļ░Ć ļŹö ņל ĒĢÖņŖĄĒĢĀ ņłś ņ׳ļŖö ņØ┤ļ»Ėņ¦Ć ļ░Å ņł½ņ×ÉļōżļĪ£ ņČĢņåī ļ░Å ļ│ĆĒÖśļÉśņŚłņ£╝ļ»ĆļĪ£ ĒĢÖņŖĄņØ┤ ļŹö ĒÜ©ņ£©ņĀüņ£╝ļĪ£ ļÉĀ ņłś ņ׳ļŖö Ļ▓āņØ┤ļØ╝Ļ│Ā ņśłņāüļÉ£ļŗż. ĻĘĖ ņÖĖ ĻĖ░ņ¦ĆņāüņØĖ ĒÄśļØ╝ņØ┤ĒŖĖņÖĆ ĒÄäļØ╝ņØ┤ĒŖĖ ņĪ░ņ¦üņØĆ ĒØæņŚ░ņāüņŚÉ ļ╣äĒĢ┤ ĒŖ╣ņ¦ĢņØ┤ ņĢĮĒĢ┤ ņØ┤ņŚÉ ļīĆĒĢ£ ĒŖ╣ņ¦ĢņČöņČ£ņØĆ Ļ▒░ņØś ņØ┤ļŻ©ņ¢┤ņ¦Ćņ¦Ć ņĢŖņØĆ Ļ▓āņ£╝ļĪ£ ĒīÉļŗ©ļÉ£ļŗż.
ņØ┤ņĀä ņŚ░ĻĄ¼ļōżņŚÉņä£ ļ│┤ļ®┤ CNNņŚÉņä£ļŖö Ļ│äņĖĄņØ┤ Ļ╣Ŗņ¢┤ņ¦łņłśļĪØ ņČöņČ£ļÉśļŖö ņĀĢļ│┤Ļ░Ć ļŹöņÜ▒ ĻĄ¼ņ▓┤ĒÖöļÉ£ļŗżĻ│Ā ņĢīļĀżņĀĖ ņ׳ļŗż. ņ┤łĻĖ░ņØś ĒĢ®ņä▒Ļ│▒ Ļ│äņĖĄņŚÉņä£ļŖö ļŗ©ņł£ĒĢ£ ņ£żĻ│ĮņäĀņŚÉ ļ░śņØæĒĢśĻ│Ā, ņØ┤ņ¢┤ņä£ ĒģŹņŖżņ▓śņŚÉ ļ░śņØæĒĢśĻ│Ā, ļŹöņÜ▒ ļ│Ąņ×ĪĒĢ£ ņé¼ļ¼╝ņØś ņØ╝ļČĆņŚÉ ļ░śņØæĒĢśļÅäļĪØ ļ│ĆĒÖöĒĢ£ļŗżĻ│Ā ĒĢ£ļŗż[18,19]. ņØ┤ņĀä CNN ņŚ░ĻĄ¼ļŖö ņ×¼ļŻīņØś ļ»ĖņäĖņĪ░ņ¦ü ļČäņĢ╝Ļ░Ć ņĢäļŗī ļÅÖļ¼╝ņØ┤ļéś ņé¼ļ¼╝ ļō▒ ņØ╝ļ░śņĀüņØĖ ļ¼╝ņ▓┤ņØś ņØ┤ļ»Ėņ¦ĆņŚÉ ļīĆĒĢ£ ņŚ░ĻĄ¼Ļ░Ć ņ¦äĒ¢ēļÉśņ¢┤ ņÖöļŗż. ņśłļź╝ ļōżņ¢┤ ņ×ÉļÅÖņ░©ļéś ņŗ£Ļ│ä ļō▒ņØś ņØ┤ļ»Ėņ¦Ć ņŗØļ│äņŚÉ CNNņØä ņØ┤ņÜ®ĒĢĀ ļĢīņŚÉļŖö ļīĆļČĆļČä ņé¼ļ¼╝ ĒĢ£ Ļ░£ļ¦ī ņĪ┤ņ×¼ĒĢśļŖö ņØ┤ļ»Ėņ¦Ćļ¦īņØä ļČäņäØĒĢśņśĆļŗż. ĻĘĖļ¤¼ļéś, ņ×¼ļŻīņØś ļ»ĖņäĖņĪ░ņ¦üņØĆ Ļ▓░ņĀĢļ”ĮņØ┤ļéś ĒØæņŚ░ņāü ļō▒ņØś ņĀ£2ņāüņØ┤ ļČłĻĘ£ņ╣ÖĒĢ£ Ēī©Ēä┤ņ£╝ļĪ£ ņØ┤ļŻ©ņ¢┤ņĀĖ ņ׳ļŗż. ļ»ĖņäĖņĪ░ņ¦ü ņØ┤ļ»Ėņ¦ĆņŚÉņä£ļŖö ņØ┤ļ¤¼ĒĢ£ ņĀ£2ņāüņØ┤ ļŗ© ĒĢ£ ņóģļźś, ļŗ© ĒĢ£ Ļ░£ļ¦ī ņĪ┤ņ×¼ĒĢśļŖö Ļ▓āņØ┤ ņĢäļŗłļ»ĆļĪ£, ļ│ĄĒĢ®ņĀüņØĖ ņŗØļ│äņŚÉ ļīĆĒĢ£ ĒĢÖņŖĄņØ┤ ņłśĒ¢ēļÉśņŚłļŗżĻ│Ā ĒīÉļŗ©ļÉ£ļŗż. ļ│ĖņŚ░ĻĄ¼ņØś Ļ▓ĮņÜ░ņÖĆ Ļ░ÖņØ┤ ņäØņČ£ļ¼╝Ļ│╝ ņĀĢņČ£ļ¼╝ ļō▒ ņĀ£2ņāüņØ┤ ņŻ╝ļĪ£ Ļ┤Ćņ░░ļÉśļŖö ĒĢ®ĻĖłņØś ļ»ĖņäĖņĪ░ņ¦üņŚÉņä£ļŖö Ļ░ü ņĀ£2ņāü ņóģļźśņŚÉ ļö░ļźĖ ĒĢÖņŖĄņØ┤ ņżæņÜöĒĢśļ®░, ņØ┤ņŚÉ ļīĆĒĢ£ ņØ┤ļ»Ėņ¦Ć ļČäņäØ ļŹ░ņØ┤Ēä░ ļ▓ĀņØ┤ņŖżĻ░Ć ĻĄ¼ņČĢļÉśļ®┤ ņĀ£2ņāüņØś ĒśĢĒā£ļĪ£ ĒĢ®ĻĖłņØś ņóģļźśļź╝ ļČäļźśĒĢśļŖö ņŚ░ĻĄ¼Ļ░Ć Ļ░ĆļŖźĒĢĀ Ļ▓āņ£╝ļĪ£ ļ│┤ņØĖļŗż. ņØ┤ļź╝ ņ£äĒĢ┤ņä£ļŖö ļŗ©ņł£ĒĢ£ CNNļ┐Éļ¦īņĢäļŗłļØ╝ ņĀ£2ņāüņØś ņé¼ļ¼╝ņŗØļ│ä(object detection) [20]Ļ│╝ ņØśļ»ĖļČäĒĢĀ(semantic segmentation) [21]ņŚÉ Ļ┤ĆĒĢ£ ņŚ░ĻĄ¼ļÅä ĒĢäņÜöĒĢśļŗż. ĒĢ£ĒÄĖ, ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ĻĖ░ņ¦ĆņāüņØ┤ ļŗ©ņł£ĒĢśņŚ¼ Ļ▓░ņĀĢļ”ĮĻ│äļéś ņłśņ¦ĆņāüņĀĢ ļō▒ņØś ļ»ĖņäĖņĪ░ņ¦ü Ēī©Ēä┤ņØĆ ņĀäĒśĆ Ļ│ĀļĀżĻ░Ć ļÉśņ¦Ć ņĢŖņĢśļŖöļŹ░, ņØ┤ņŚÉ ļīĆĒĢ£ ņČöĻ░ĆņĀüņØĖ ņŚ░ĻĄ¼ļÅä ņÜöĻĄ¼ļÉ£ļŗż.
4. Ļ▓░ ļĪĀ
ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ĻĄ¼ņāüĒØæņŚ░ņŻ╝ņ▓ĀĻ│╝ ĒÜīņŻ╝ņ▓ĀņØś ļ»ĖņäĖņĪ░ņ¦ü ņØ┤ļ»Ėņ¦Ćļź╝ ļČäļźśĒĢśĻĖ░ ņ£äĒĢśņŚ¼ ļŗ©ņł£ĒĢ£ ĒśĢĒā£ņØś ĒĢ®ņä▒Ļ│▒ ņŗĀĻ▓Įļ¦ØņØä ĻĄ¼ņČĢĒĢśņŚ¼ ĻĖ░Ļ│äĒĢÖņŖĄņØä ņłśĒ¢ēĒĢśņśĆļŗż. ĻĖ░Ļ│äĒĢÖņŖĄ ņżæ ņŗ£ņŖżĒģ£ņØ┤ ņ¢┤ļ¢ż ĻĘ╝Ļ▒░ļĪ£ ļ»ĖņäĖņĪ░ņ¦ü ņØ┤ļ»Ėņ¦Ćļź╝ ņØĖņŗØĒĢśļŖöņ¦Ć Ļ░ĆļŖĀĒĢśĻĖ░ ņ£äĒĢśņŚ¼ ĒĢ®ņä▒Ļ│▒ Ļ│äņĖĄ ņ¦üĒøäņØś ņżæĻ░äņĖĄ ņØ┤ļ»Ėņ¦Ćļź╝ ņČöņČ£ĒĢśņŚ¼ ļČäņäØĒĢśņśĆļŗż. ņØ┤ņŚÉ ļŗżņØīĻ│╝ Ļ░ÖņØĆ Ļ▓░ļĪĀņØä ņ¢╗ņŚłļŗż.
1) ĻĖ░Ļ│äĒĢÖņŖĄ Ēøä ļČäņäØĒĢśĻ│Āņ×É ĒĢśļŖö ņŗ£ĒÄĖ, ņ”ē ĻĄ¼ņāüĒØæņŚ░ņŻ╝ņ▓ĀĻ│╝ ĒÜīņŻ╝ņ▓Ā ņŗ£ĒÄĖņØś ļ»ĖņäĖņĪ░ņ¦ü ņØ┤ļ»Ėņ¦Ćļź╝ ņ×ģļĀźĒĢśņśĆņØä ļĢī, 98% ņØ┤ņāüņØś ļåÆņØĆ ņĀĢĒÖĢļÅäļĪ£ ņŗ£ĒÄĖņØś ņóģļźśļź╝ ļČäļźśĒĢĀ ņłś ņ׳ņŚłļŗż.
2) ĒĢ®ņä▒Ļ│▒ņŗĀĻ▓Įļ¦ØņŚÉņä£ ĒĢ®ņä▒Ļ│▒Ļ│äņĖĄĻ│╝ ĒÆĆļ¦üĻ│äņĖĄņØä ĒåĄĻ│╝ĒĢĀ ļĢī ņŚ░ņé░ņØś ĒŖ╣ņä▒ņŚÉ ļö░ļØ╝ ņØ┤ļ»Ėņ¦ĆļŖö Ļ│äņåŹ ņČĢņåīļÉśņ¢┤, ņĄ£ņóģņĀüņ£╝ļĪ£ļŖö ņÖäņĀäĻ▓░ĒĢ®Ļ│äņĖĄņŚÉ ņŚ░Ļ▓░ļÉĀ ņłś ņ׳ļŖö ņĀüņĀłĒĢ£ ņ×æņØĆ Ēü¼ĻĖ░ļĪ£ ņżäņ¢┤ļōżņŚłļŗż. ņØ┤ļĢī ņØ┤ļ»Ėņ¦ĆļŖö ņ┤łĻĖ░ ņØ┤ļ»Ėņ¦ĆņØś ļŗ©ņł£ ņČĢņåīĻ░Ć ņĢäļŗī, ļ»ĖņäĖņĪ░ņ¦üņŚÉņä£ Ļ░Ćņן ĒŖ╣ņ¦ĢņĀüņØĖ ļČĆļČäņØä ņČöņČ£ĒĢśņŚ¼ ņČĢņåīĒĢśļŖö Ļ▓āņ£╝ļĪ£ ĒīÉļŗ©ļÉ£ļŗż.
3) ĒĢ®ņä▒Ļ│▒ņŗĀĻ▓Įļ¦ØņØĆ ņżæĻ░äĻ│╝ņĀĢņŚÉņä£ ņ¢┤ļ¢ĀĒĢ£ ļ░®ļ▓Ģņ£╝ļĪ£ ņØ┤ļ»Ėņ¦Ćļź╝ ļČäļźśĒĢśļŖöņ¦Ć ĻĘĖ ĻĘ╝Ļ▒░ļź╝ ņé¼ņÜ®ņ×ÉņŚÉĻ▓ī ņĀ£ņŗ£ĒĢśņ¦Ć ņĢŖņ¦Ćļ¦ī, ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ņżæĻ░äņĖĄņŚÉņä£ņØś ņØ┤ļ»Ėņ¦Ćļź╝ ņČöņČ£ĒĢśņŚ¼ ņØ┤ļź╝ ļČäņäØĒĢśņśĆļŗż. ņØ┤ļ¤¼ĒĢ£ ņØ┤ļ»Ėņ¦Ćļź╝ ĻĘ╝Ļ▒░ļĪ£ ļ»ĖļŻ©ņ¢┤ļ│┤ļ®┤, ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ ĻĄ¼ņČĢĒĢ£ ĒĢ®ņä▒Ļ│▒ņŗĀĻ▓Įļ¦ØņØĆ ņŻ╝ņ▓ĀņØś ļ»ĖņäĖņĪ░ņ¦ü ņżæ ņŻ╝ļĪ£ Ļ░ü ĒØæņŚ░ņāüņØś ĒśĢĒā£ņŚÉ ļīĆĒĢ£ ĒŖ╣ņ¦ĢņØä ņČöņČ£ĒĢśņŚ¼ ļČäļźśņØś ĻĖ░ņżĆņ£╝ļĪ£ ņé╝ļŖö Ļ▓āņ£╝ļĪ£ ĒīÉļŗ©ļÉ£ļŗż.