화상인식을 이용한 Al-Si 주조용 합금의 화학조성 예측
Estimation of Chemical Composition of Al-Si Cast Alloys Using Image Recognition
Article information
Trans Abstract
In this study, we analyzed the chemical composition of Al-Si cast alloys from microstructural images, using image recognition and machine learning. Binary Al-Si alloys of Si = 1~10 wt% were cast and prepared as reference images in the dataset used for machine learning. The machine learning procedure was constructed with Inception V3 model. Repeated training to relate the microstructural images to their chemical composition was carried out, for up to 10,000 steps, to increase the reliability of the analysis. The peaks of similarity existed in the dataset with chemical compositions corresponding to the known target composition. The heights of the peaks became higher and the distribution of similarity became sharper with further training steps. This means that the weighted average of the chemical composition approached the target composition with increasing training steps. The correctness of the analysis increased with training steps up to 10,000, then was saturated. It was found that the chemical composition outside the dataset range could not be analyzed correctly. Analysis of the compositions between the datasets showed incorrect but reasonable results. The reliability of the chemical composition analysis using machine learning and image recognition developed in this study will increase when a vast range of reference images are collected and verified.
1. 서 론
최근 들어 제4차 산업혁명에 대한 관심이 높아지고, 특히 인공지능(artificial intelligence)를 공학과 과학 분야에 접목하고자 하는 노력이 증가하고 있다. 현재 공학 분야에 적용중인 인공지능 분야는 전문가 시스템(expert system) [1,2], 컴퓨터 비전(computer vision)[3], 자연어 처리(natural language processing)[4] 등이 있으며, 이들은 기계학습(machine learning)을 이용하여 활발히 연구되고 있다. 기계학습[5,6]은 많은 공학적 데이터를 컴퓨터 알고리즘을 통해 분석하는 기술로, 현재 관련된 많은 알고리즘이 개발되고 있다.
최근까지 기계학습은 일반적으로 새로운 학습기법이나 효율성을 높이는 개발 중심으로 연구가 진행되어 왔다. 기계학습을 공학에 응용하기 위해서는 정확한 과학적 문제의 정의가 중요하다. 즉, 어떠한 공정에 대한 X인자와 Y인자를 정의하고 두 인자 간의 상관관계를 기계학습을 이용하여 파악하고 공정의 최적방안을 찾아내야 하는데, 이때 어떤 기계학습 알고리즘을 적용하는가, 어떻게 데이터를 이해하고 입력을 해야 하는가가 중요한 요소가 된다. 최근 데이터를 분류하는 알고리즘에는 의사결정나무(decision tree)[7], 베이지안 망(Bayesian network)[8], 서포트 벡터머신(support vector machine, SVM)[9], 인공신경망(artificial neural network, ANN)[10,11], 합성곱 신경망(convolutional neural network, CNN)[12] 등이 대표적으로 사용되고 있다. 이중 CNN 모델은 이미지 인식과 음성인식, 자연어 처리 등에 뛰어난 성능을 가지며, CNN 모델에 대해서는 여러 다양한 파생 신경망이 개발, 응용되어 사용되고 있다.
한편 요즘 각광받고 있는 스마트 팩토리(smart factory)는 기계학습을 이용한 인공지능을 산업에 응용하는 가장 좋은 사례로 꼽히고 있고 많은 연구가 진행되고 있다. 그러나 인공지능이나 기계학습의 개념을 실제 공학과 과학의 연구에 적용시키는 연구는 아직 미미하다.
본 연구에서는 이러한 기계학습을 재료공학, 특히 금속재료에서의 미세조직을 자동적으로 분류하고 분석하는 방법론에 대해 논하고자 한다. 잘 알려진 바와 같이 금속의 미세조직은 합금성분과 제조공정에 의하여 변화하며 각기 독자적인 미세조직의 모양을 나타낸다. 따라서, 미세조직을 기계학습을 통해 분석한다면, 미세조직 사진만으로도 합금의 성분과 그 제조방법을 알 수 있는 기술의 개발이 가능하다. 금속의 공정을 고정한 경우, 합금의 화학조성을 X인자로 지정하면 결과적인 미세조직을 Y인자로서 고려하는 것이 현재까지 진행되어온 전통적인 연구방법이다. 또한 현재까지는 결정립의 크기나 상의 분포 등 일부 정량적인 분석을 제외한 상의 형태 등 정성분석은 사람의 육안으로 분석해왔다. 만약 화상 분석에 의한 기계학습을 이용하여 미세조직을 분류하고 판별할 수 있다면 재료공학 연구에 큰 도움이 될 수 있다. 화학조성과 미세조직 이미지에 대한 빅테이터를 구축한 후, 위에서 언급한 전통적인 방법과 달리, Y인자인 미세조직으로써 X인자인 합금의 화학조성을 이끌어 낼 수 있다면, 미세조직 이미지만으로 합금의 성분을 유추할 수 있는 시스템 구축이 가능하다.
본 연구에서는 Al-Si 이원계 주조 합금을 기반으로, 컴퓨터에 의한 미세조직 이미지 인식과 기계학습을 이용하여, 이러한 분석 과정을 구성하고 그 실용성과 한계를 고찰하고자 한다. 이를 통해 분석시간의 단축 및 분석 오류횟수를 감소시킬 수 있다.
금속재료 미세조직의 이미지 분석과 분류는 이미지에 대한 기계학습 중 가장 적합하다고 알려진 CNN 모델을 이용하였다. 단, 기계학습을 위해서는 수많은 미세조직 이미지와 이에 상응하는 재료특성 데이터가 있어야 하며, 이에 대한 자료 수집이 우선적으로 요구된다. 본 연구에서는 기존에 수집되고 정리된 많은 이미지 데이터를 활용하고, 기계학습의 한 분야인 지도학습(supervised learning) 알고리즘을 이용, 특성 미세조직과 이에 대응하는 재료의 성분이나 특성을 연결시켜 새로운 이미지가 주어졌을 때 이미지만으로 재료의 화학성분이나 특성을 예측할 수 있는 기법을 개발하고자 한다.
2. 화상인식에 대한 기계학습
인공신경망(artificial neural network)[11]은 생물학적 뉴런의 동작원리와 뉴런 간의 관계를 모델링한 것으로 노드와 레이어 구조의 형태로 연결된 정보처리 시스템이다. 인공신경망 모델은 단층 신경망과 다층 신경망으로 구분된다. 단층 신경망은 선형분류함수로서 두 집단 간의 데이터를 분류하지만, 선형함수로 분류가 불가능한 경우 비선형함수로 분류하는 다층신경망을 사용한다. 다층 신경망의 경우 일반적으로 입력층과 은닉층, 출력층으로 구성되며 각 층은 여러 개의 노드를 가질 수 있어 다양한 형태의 네트워크로 표현될 수 있으며, 이러한 신경망을 이용한 학습방법을 딥러닝(deep learning)[13] 이라 한다. 딥 러닝은 인공신경망을 이용하여 데이터를 군집화 또는 분류하는데 사용되고 있다. 금속의 미세조직 이미지 인식을 위하여, 본 연구에서는 화상인식을 구현하기 위한 가장 용이한 구글(Google)에서 개발한 텐서플로우(Tensorflow)[14]라고 하는 오픈 라이브러리 소스를 통한 딥러닝을 이용하였다.
텐서플로우를 기반으로 하는 다중 신경망 모델을 구축하기 위한 많은 알고리즘이 개발되었다. 본 연구에서는 그중 화상인식에 대한 기계학습에 가장 적합도가 높은 신경망 모델인 인셉션(Inception) V3 모델[15]을 사용하였다. 기존 CNN모델은 층마다 하나의 크기를 가지는 컨볼루션(convolution) 필터를 사용하는 반면, 본 연구에서 사용한 인셉션(Inception) V3 모델은 한 층에 여러 크기의 컨볼루션 필터를 사용하여 이미지를 여러 크기의 관점에서 보는 효과적인 특징을 추출할 수 있는 구조의 모델이다. 그림 1에서 나타낸 바와 같이 한 층의 인셉션 V3 모듈의 구조는 기존의 컨볼루션 층보다 복잡하지만 3 × 3과 5 × 5 깊이를 1 × 1 필터의 개수로 통제함으로써 여러 층의 표현을 더 함축하여 표현이 가능하다.
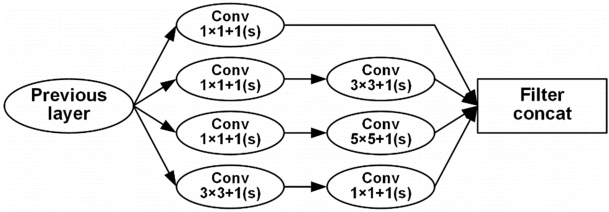
Schematic structure of the base module of Inception V3.
본 연구에서의 미세조직 이미지 분석 과정을 그림 2에 개략적으로 나타내었다. 학습을 위해 먼저 텐서플로우를 이용하여 데이터셋으로 이용할 사진을 저장하였다. 사진들은 딥러닝을 위한 반복학습을 위해 각 디렉토리로 나뉘어 보관하였다. 이를 통해 디렉토리 별로 미세조직 이미지에 대한 신경망 그래프가 생성된다. 학습을 통해 생성된 신경망 그래프 데이터셋을 기반으로, 새로운 이미지를 입력하면 전술한 데이터셋과 비교를 수행하여 새로이 입력된 이미지와 가장 유사한 데이터셋에 대한 정보를 제공한다.

Schematic process of image recognition using machine learning.
3. Al-Si 시편 준비
3.1 Al-Si 주조 시편의 제작
Al-Si계 합금은 가장 일반적인 주조용 Al 합금계로, 산업용 주조에 사용되는 Al 합금 중 사용 비중이 90% 이상을 차지한다 [16,17]. 이원계 Al-Si 합금은 공정합금으로, 공정온도는 577 ℃이며, 공정조성에서의 Si 함유량은 약 12.5 wt%이다. Al이 주성분이 되는 α상은 Si의 최대고용률이 공정온도에서 1.65 wt%이나 Si상에 Al의 고용률이 거의 없어, 이원계 Al-Si 합금을 주조할 때 발생하는 Si상은 Al을 포함하지 않는 순수한 Si상이다.
본 실험에서는 Si = 1~10 wt%에서 1 wt% 간격으로 합금을 제작하였다. 이원계 Al 합금을 전기로에서 용해한 후, 그림 3에서 나타낸 것과 같은 계단식 주형에 용탕을 주입하였다. 계단식 주형을 사용한 이유는, 각 계단에서의 폭이 다르면 계단마다 응고중 냉각조건도 상이하여, 한 번의 주조로 냉각조건이 다른 여러 시편을 얻을 수 있기 때문이다 [18]. 주형은 약 200 ℃로 예열하였으며, 용탕의 주입 온도는 약 750 ℃로 일정하게 설정하였다. 응고중 냉각속도는 Si = 1 wt%에 대하여 14.9 ºC/s (TC1) ~3.1 ºC/s (TC4)의 범위를 나타내었고, Si = 10 wt%에 대해서는 4.8 ºC/s (TC1) ~0.8 ºC/s (TC4)의 범위를 나타내었다. 응고가 완료된 후에는 시편을 채취하였다. 이 시편은 연마와 미세연마과정을 거쳐 켈러 시약(Keller's reagent: 95% H2O, 2.5% HNO3, 1.5% HCl, 1.0% HF)로 화학부식한 후, 광학현미경으로 미세조직을 관찰하였다.
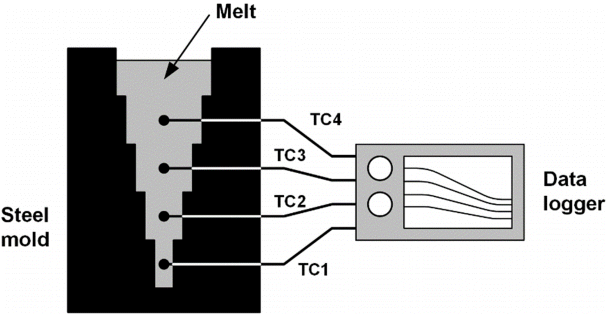
Schematic of casting process for Al-Si alloys using a step mold.
이와 같이 관찰한 Al-Si 합금의 미세조직의 일부를 그림 4에 나타내었다. 본 실험에서 제작한 합금은 Si의 함유량이 공정조성보다 적은 아공정합금으로, 기본적으로 Al 원소가 주를 이루는 α상이 응고초기에 발생하여 수지상정으로 성장하고, 공정온도에 다다르면 공정조성을 갖는 잔여 액체가 응고한 공정조직이 생성된다. 본 연구에서도 이에 상응하여 Si의 함량이 증가함에 따라 α 수지상정의 제이차 수지상간격이 감소하며, 공정조직의 양도 함께 증가하였다.

Sample images of Al-Si alloys for dataset of machine learning used in this study.
3.2 미세조직 이미지의 전처리
광학 현미경으로 미세조직을 촬영할 때의 배율은 ×50과 ×100, ×200이었다. 광학 현미경으로 촬영한 미세조직 이미지의 크기는 2048 × 1536 픽셀이며, 흑백으로 보이지만 실제로는 색상정보를 담고 있다. 또한 모든 미세조직의 이미지는 축척표시(scale bar)를 가지고 있다. 본 연구에서 미세조직 이미지에 대한 데이터셋을 구축하기에 앞서 다음과 같이 레퍼런스 이미지에 대한 전처리를 수행하였다.
컬러 사진을 흑백으로 전환하고, 명암비를 가능한 한 다른 시편과 유사하게 조정하였다. 이는 컬러 정보나 명암상태로서 미세조직 이미지를 인식할 수 있을 가능성을 최소화하기 위함이다. 축척표시는 화상인식에 방해가 되므로 이미지 부분에서 축척표시 부분을 삭제하고, 2048 × 1310 픽셀만을 남겼다. 이 처리를 통하여, 각 이미지에 대한 촬영 배율에 대한 정보는 모두 삭제되었다. 위와 같은 전처리를 통하여, 조성이 다른 합금 시편당 서로 다른 50장의 이미지를 준비하였다.
한 종류의 시편에 대하여, 이미 냉각속도가 다른 부분의 시편의 이미지가 혼합되어 있으며, 여러 배율의 사진이 정보 없이 혼재되었다. 냉각속도의 영향을 배제한 이유는, 상용 제품으로 본 연구에서와 같이 이미지 인식을 통한 합금 조성 분석을 할 때 주조 제품의 부분에 따라 냉각속도가 모두 달라지기 때문에 냉각속도의 영향에 관계없이 합금 조성을 추측할 수 있는가를 시험하기 위해서이다. 물론 합금 조성과 함께 냉각속도도 미세조직에 큰 영향을 미친다. 그러나 냉각속도까지 예측하기 위해서는 현재보다도 더욱 방대한 데이터가 요구된다. 본 연구에서는 기초적인 연구를 진행함에 있어서, 냉각속도의 영향을 배제하였다. 여러 배율이 혼재되어 있는 이유는 다음과 같다. 일반적으로 광학현미경에 장치되어 있는 디지털 카메라로 미세조직을 촬영하면, 같은 배율로 관찰하였다 하더라도 우리가 디지털 파일로 얻을 수 있는 화상의 해상도는 달라질 수 있다. 인터넷 자료나 논문 자료에서는 실제로 촬영한 화상의 해상도를 그대로 나타내기 어려우며, 축척표시 없이는 미세조직의 길이 정보는 얻을 수 없다. 예를 들어 인터넷에서 수집한 사진을 화상인식을 통하여 합금 성분을 예측할 때에는 정확한 크기 정보를 얻기 어렵다. 그러므로 본 연구에서는 축척표시가 없는 사진을 사용하였으며, 여러가지 배율이 혼재된 사진을 사용하였다.
신뢰도 높은 데이터셋을 구축하기 위해서는 보다 많은 수의 이미지가 필요하다. 그러나 현실적으로 한 시편당 수백 장 이상의 이미지를 얻는 것에는 어려운 점이 많다. 그러므로, 다음과 같이 시편당 기본(basic) 이미지 50장과 함께, 변환된 이미지를 추가적으로 사용하고 그 효과를 고찰하였다.
(a)기본 이미지 50장 +좌우반전(reversed) 이미지 50장 =총 100장.
(b)기본 이미지 50장 +반쪽(half) 이미지 100장 =총 150장. 기본 이미지를 반쪽(1024×1310 픽셀)으로 분리
(c) 기본 이미지 50장 + 반전 이미지 50장 + 기본 이미지의 반쪽 이미지 100장 + 반전 이미지의 반쪽 이미지 100장 =총 300장.
4. 결과 및 고찰
4.1 화상인식을 통한 합금성분의 역산출
그림 4에서 나타낸 Al-Si 합금의 미세조직을 살펴보면, 전술한 바와 같이 Si의 함량이 높아질수록 수지상정이 미세해지고 Al-Si 공정조직의 양이 증가함을 쉽게 확인할 수 있다. 특히 Al-1 wt%Si 합금과 Al-10 wt%Si 합금의 이미지를 정확한 합금 조성에 대한 정보없이 육안으로 비교해보면, 적어도 Al-10 wt%Si 합금이 Al-1 wt% 합금에 비하여 공정조직의 양이 많으며, 수지상정이 잘 발달한 것을 확인할 수 있으므로, 어느 시편의 Si 함량이 높은지 판단이 가능하다. 한편, Al-5 wt%Si 합금과 Al-6 wt%Si 합금의 사진을 비교하면, 수지상정의 형태가 유사하고 공정조직의 양이 비슷하여, 추가적인 정보없이 육안으로 합금의 상대적인 조성에 대한 판단하기는 쉽지 않다.
시편의 미세조직 이미지에 대한 데이터셋을 구축하기 위하여 Si = 1~10 wt% 조성의 합금의 기본(basic) 이미지를 한 가지 조성당 50장씩 준비하여 기계학습을 수행하였다. 이미지에 대한 기계학습은 반복학습이 요구되는데, 반복횟수의 영향을 알아보기 위하여, 10,000번까지 1000번 단위로 학습하고 화상인식을 시도하였다. 조성예측 단계에서는, 데이터셋에 포함되지 않고 조성이 이미 알려진 이미지를 입력하였다. 그 결과의 일부를 그림 5에 나타내었다. 그림에는 시편의 목표(target) 조성은 Si 함량 범위의 한계인 1과 10 wt%와, 범위 사이의 4와 7 wt%를 나타내었다. 반복학습의 횟수에 관계없이, 어느 목표 조성에서나 우리가 이미 알고 있는 조성에서 피크가 관찰되었다. 예를 들어 시험 시편의 합금이 Al-4 wt%Si인 경우 Si = 4 wt%에서 피크를 나타내었으며, 이 피크를 중심으로 정규분포와 유사한 분포를 가지는 것을 확인할 수 있다. 이러한 현상은 Si = 7 wt%에서도 유사하게 발견된다. 학습횟수가 증가함에 따라 피크에서의 유사도(similarity)도 함께 증가하고 피크의 폭은 좁아지는 경향을 나타내었다. 이는 학습횟수가 많을수록 화상인식의 신뢰도가 높아지는 사실을 보여주고 있다. 본 연구에서는 학습의 반복횟수가 10,000번 이상에서는 정확도의 변화가 더이상 관찰되지 않았다.

Similarity distribution evolved with training step for (a) Al-1 wt%Si, (b) Al-4 wt%Si, (c) Al-7wt%Si, and (d) Al-10 wt%Si alloys.
여기에서 한가지 주목해야 할 사실은 각 조성에 대한 유사도의 합은 언제나 100%라는 것이다. 이미 구성된 데이터셋과 비교한 결과를 유사도로 나타내는 인셉션 V3 모델의 특성상, 이미지의 비교는 절대적인 수치가 아닌 상대적인 수치라는 것을 알 수 있다.
한편, 1과 10 wt%는 Si 함량 범위의 한계 조성이므로, 조성 분포는 목표 조성을 기준으로 반쪽 분포 형태로 나타났다. 그림 5(d)의 Al-10 wt%Si 합금의 경우와 같이, 목표조성 근처가 아닌 다른 조성에서도 작은 피크가 발견되는데, 학습횟수가 증가하면서 이러한 피크의 크기는 감소하였다.
피크 위치의 합금조성을 결과로 사용할 수도 있겠지만, 조금 더 자세하고 정량적인 결과를 얻기 위하여, 각 조성에서의 유사도를 가중치로 사용하여 Si 평균 함량을 계산하였다. 이 결과를 그림 6에 나타내었다. 9나 10 wt%Si의 경우와 같이 학습 반복횟수가 적을 때에는 Si 함량과 목표조성의 차이가 큰 경우가 있다. 그러나, 학습횟수가 증가할수록 목표 조성에 근접하였다. 당연하게도 Si 함량 범위의 한계(1 wt%와 10 wt%) 밖의 조성은 전혀 나타나지 않았다. 1과 2 wt%의 경우에는 목표조성보다 높게, 9와 10 wt%의 경우에는 목표조성보다 낮게 나와, 다른 조성과는 달리 목표조성의 근접성이 낮다고 판단된다. 이러한 현상은 학습횟수가 적을 때 더 두드러진다. 이는 범위 한계 부근의 조성은 좌우대칭의 분포를 얻기 어렵기 때문이라고 판단된다. Si = 10 wt%의 예를 들면, 10 wt%에서의 유사도가 100%인 경우만 제외하면, 이 시편의 평균 조성은 10 wt%보다 작게 예측될 수 밖에 없다는 것이다. 전체 데이터셋을 구성하는 레퍼런스 이미지의 수량을 늘리고 학습 반복횟수도 증가시키면, 범위 한계 부근의 조성을 포함한 전 영역에서, 전체적인 예측 정확도가 향상될 것이라고 판단된다.

Weight-averaged Si contents of the alloys. These values approached to the accurate value as training step increased.
또한, 레퍼런스 이미지에는 미세조직 촬영 이미지의 배율이 각기 다른 사진들이 포함되어 있으며, 같은 조성내의 시편에서도 시편에 따라 냉각속도가 달라 제이차수지상간격이 다른 시편의 이미지가 혼재되어 있다는 사실을 염두해 둘 필요가 있다. 다시 말하면 동일한 데이터셋내에는 같은 조성이긴 하지만, 부분적으로 공정조건이 다른 시편이 포함될 수 있다. 컴퓨터에 의하여 화상인식을 진행할 때, 크기나 길이와 같은 정량적인 데이터는 이미지의 유사도와는 크게 상관이 없는 것으로 판단된다.
4.2 레퍼런스 이미지의 확보 방안
그림 7은 기본 이미지만으로 10,000번 반복학습 하였을 때의 목표 조성과 결과적인 예측 조성을 나타낸 결과이다. 다소 서로간의 오차가 있으나 전체적으로 목표 조성의 예측 수준이 준수하다고 판단된다. 이 데이터셋을 기본으로 3.2절에 설명한 바와 같이 반전 이미지와 반쪽 이미지를 이용하여 데이터셋의 양을 증가시킨 후 10,000번 반복 학습한 결과를 그림 7(a)에 같이 나타내었다. 결과적으로 반전 이미지와 반쪽 이미지를 포함시킨 데이터셋으로 학습하는 것은 전체적인 예측의 정확도에는 큰 영향을 주지 못했다. 이 결과의 선형회귀분석은 그림 7(b)에 나타내었다. 이때 선형 함수는 y = ax + b로 나타내었다. 분석결과와 목표조성은 각각 x와 y로 나타내었으며, a와 b는 각각 기울기와 y절편이다. R2를 고찰해 보면, 모든 경우에 있어서 0.96 이상의 값을 가져 선형에 잘 일치함을 알 수 있다. 정확한 예측이 이루어지면 a = 1과 b = 0를 만족하여야 한다. 본 연구의 결과를 분석해본 결과, 기본 이미지에 반전 이미지와 반쪽 이미지를 추가하였을 때 a가 1에 더 가까워지며 b는 0으로 접근하였다. 그러나, 그 영향은 크지 않다고 판단된다.
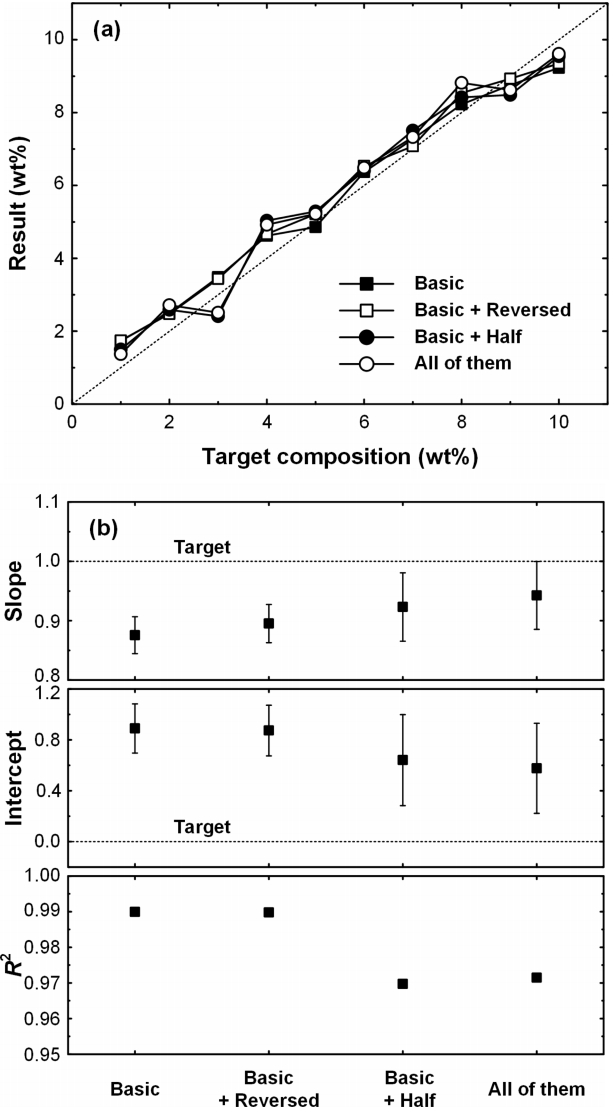
(a) The effect of the dataset made with basic images, basic and reversed images, basic and half images, and all of them, on the estimated chemical composition with respect to target composition, and (b) results of linear regression analysis.
인셉션 V3 모델에서 이미지 비교의 정확한 근거를 제시하기는 어렵다 [15]. 일반 사물의 이미지와는 달리, 금속의 미세조직은 패턴화되어 있어서 부분적으로 판단하면 같은 패턴으로 인식되는 부분이 있을 것이라고 예상된다. 그러므로, 이미지 기계학습의 신뢰도를 향상시키는 데에는, 반전 및 회전, 부분 이미지 보다는 기본적으로 제공되는 레퍼런스 이미지 수량의 확보가 가장 중요하다고 판단된다.
4.3 데이터셋 범위 밖 조성을 가진 시편의 분석
기본 데이터셋의 범위를 벗어나는 경우 결과가 어떻게 될 지를 판단하기 위하여, 전체 시편의 이미지를 사용하지 않고 Si = 3~8 wt%의 레퍼런스 이미지만으로 10,000번 학습하여 데이터셋을 구성하였다. 그 다음, 이 범위 밖에 있는 Si 함량인 2 wt%와 9 wt%의 목표 조성을 가진 시편의 이미지를 입력하여, 조성 예측을 시도하였다. 그림 8에 나타낸 바와 같이, 2 wt% 목표 조성의 경우는 현재 데이터셋의 Si 함량 범위 하한선인 3 wt%에서 피크가 발생하였다. 이와 유사하게 9 wt% 목표 조성의 경우에도 범위 상한선인 8 wt%에서 피크가 발생하였다. 다시 말하면, 목표 조성이 데이터셋 범위 밖에 있을 때에는 조성 범위 중 가장 패턴이 가장 유사하고, 이에 따라 합금 조성이 가장 비슷한 데이터셋에서 가장 높은 유사도를 얻었다. 예를 들면, 3 wt%보다 Si 함량이 적은 시편이 가질 수 있는 최소한의 Si 함량은 3 wt%이며, 9 wt%보다 높은 시편의 최대한의 Si 함량은 9 wt%인 것이다. 이와 같이 목표 조성이 데이터셋의 조성 범위를 벗어나면 정확한 조성을 예측할 수 없으므로, 목표 조성이 데이터셋의 조성 범위에 포함되어 있는지 먼저 조사하고 판단하는 것이 중요하다.

Similarity distributions of the samples with 2 and 9 wt%Si, when the dataset has the range of 3~8 wt%Si.
4.4 데이터셋 사이의 조성을 가진 시편의 분석
앞 절에서는 데이터셋 범위를 벗어나는 목표 조성에 대하여 고찰하였다. 이제 데이터셋과 그 인근 데이터셋 중간에 있는 목표 조성에 대하여 살펴보고자 한다. 3-1절에서는 Si = 1~10 wt%에 대하여 데이터셋을 구축하고, 그 데이터셋과 같은 목표 조성에 대해서 이미지 인식을 수행하였으나, 이제는 Si = 1, 3, 5, 7, 9 wt%의 데이터셋만을 구축하고, 10,000번 학습을 반복하였다. 그후, 목표 조성 Si = 2, 4, 6, 8 wt%에 대하여 이미지 인식을 수행하였다. 이때 각각 목표 조성에 대한 유사도 분포를 그림 9(a)에 나타내었다. Si = 2, 4, 6, 8 wt%에 대한 피크는 각각 Si = 3, 5, 7, 7 wt%에서 나타났다. 피크가 나타난 데이터셋의 조성만으로는 목표 조성과 동일한 예측 결과를 얻을 수 없고, 예측 결과의 피크는 목표 조성과 가장 인접한 데이터셋 조성에서 발견되었다. 유사도를 가중치로 한 결과 조성의 평균값은 그림 9(b)에 나타내었다. 8 wt%의 경우를 제외하고는 예측 결과가 목표조성보다 약 1 wt%씩 높게 나타났다. 회귀분석 결과 기울기와 y절편은 각각 0.795와 1.702 이었다. 결과적으로 현재 레퍼런스 이미지의 수량으로는 이 중간 수치의 평가가 쉽지 않았다. 보다 정확한 예측을 위해서는 위에서 언급한 바와 같이 데이터셋 구축을 위한 레퍼런스 이미지의 확보가 가장 중요하며, 특히 데이터셋 사이의 조성을 분석하기 위해서는 더 촘촘한 데이터셋 구축이 필요하다.
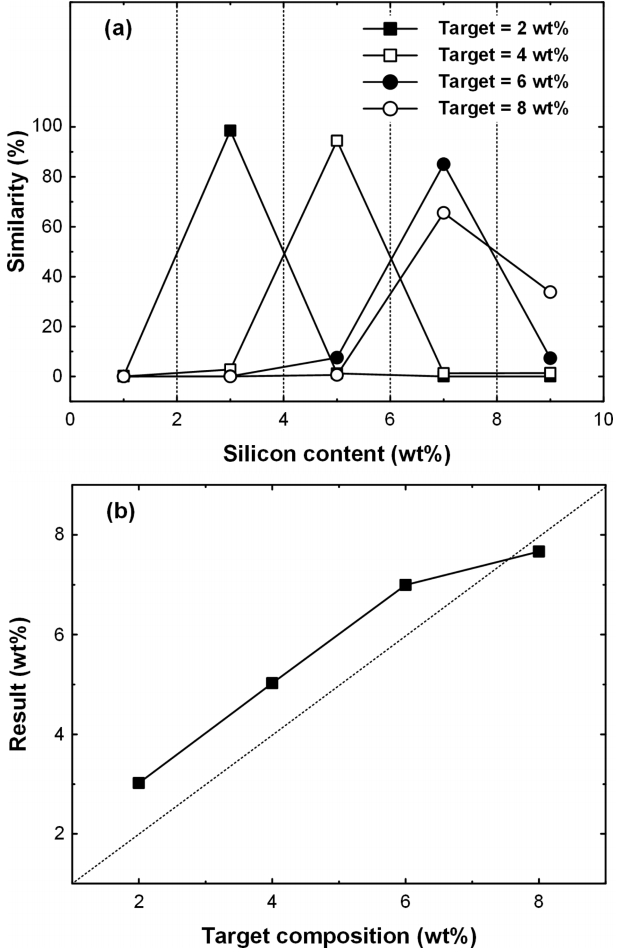
(a) Similarity distributions of the samples with 2, 4, 6, and 8wt%Si, and (b) the estimated chemical composition with respect to target composition, when the dataset contains only the samples with 1, 3, 5, 7, and 9 wt%Si.
4.5 한계와 전망
본 연구에서는 미세조직 이미지의 화상인식으로써 합금 조성을 예측할 수 있는지 그 가능성을 타진하기 위하여, 비교적 단순한 미세조직을 갖는 Al-Si 주조용 합금에 대하여 이 문제를 적용하였다. 본 연구에서 수행한 화상인식을 통한 합금 화학조성 예측은 그 시작 단계에 있다. Al-Si 합금의 미세조직의 어떤 특징에 의해서 기계 학습에서 이미지의 유사도를 판별하는지에 대해서는 앞으로 더욱 깊은 연구가 필요하다. Al-Si 합금의 경우, 육안으로 판단할 때 Al α상 수지상정과 공정상의 상비율로서 어느 정도 Si의 함량을 추측할 수 있다. 실제 기계학습에서도 같은 관점으로 이미지의 유사도가 결정되는지 확인이 필요하다. 또한 미세조직 이미지 데이터의 확보를 통하여 냉각속도의 영향과 주조결함 등 부수적인 특징에 대한 연구도 가능할 것이다.
이미지 분석을 통하여 미세조직 시편의 합금 성분을 정확하게 예측하기 위해서는 한 가지의 데이터셋에 수천 장 이상의 이미지를 필요로 한다. 우리가 산업과 연구에서 사용하는 합금의 종류는 수없이 많으며, 여기에 제조공정이라는 변수를 추가하면 어마어마한 빅데이터가 필요하다. 현실적으로 연구팀, 학교 연구실 등 하나의 기관에서 조성과 공정이 다른 합금에 대해서 이렇게 많은 수의 미세조직 데이터를 확보하는 것은 어려운 일이다. 그러므로 이러한 이미지에 대한 데이터베이스는 전세계적으로 공유할 필요가 있다. 그 방편으로 인터넷 웹사이트 등을 통한 미세조직 이미지 공유, 최종적인 재료의 특성과, 조성 및 공정 검증에 대한 데이터베이스 구축을 제안한다. 만약 이러한 공유가 일어난다면, 최초에는 미약하겠지만 데이터가 쌓일수록 그 신뢰도가 높아질 것이다. 이에 많은 사용자의 참여와 공헌으로, 산업과 연구에 큰 도움이 되리라 기대한다.
5. 결 론
본 연구에서는 Al-Si 주조합금의 미세조직 이미지를 통한 합금 성분 분석을 위하여, 텐서플로우의 인셉션 V3 모델을 이용하여 이미지 인식에 대한 기계학습을 실시하였다. 이때 합금 중 Si의 함량은 1~10 wt%으로 1 wt% 간격으로 데이터셋을 구축하였다. 그리고 이미지 인식을 통한 성분 분석 결과 다음과 같은 결론을 얻을 수 있었다.
1. 분석하고자 하는 시편의 이미지를 입력하였을 때 우리가 이미 알고있는 목표조성과 가장 가까운 합금 조성을 가진 데이터셋에서 가장 높은 유사도가 나타났다. 예측 결과의 평균 합금 조성은 학습 반복횟수가 높아질수록 목표 조성에 근접하였다.
2. 데이터의 확보를 위하여 레퍼런스 이미지의 양을 확보하는 것이 중요한데, 이를 위하여 원본 이미지를 반전시키거나 반쪽을 자른 이미지를 추가하여 데이터의 양을 확대하였다. 그러나 이러한 이미지 처리는 예측 결과의 정확도에 크게 영향을 미치지 않았다.
3. 데이터셋의 범위를 벗어나는 합금 조성을 갖는 시편의 성분의 예측과 분석은 가능하지 않았다. 데이터셋과 데이터셋 사이의 중간 조성에 대한 성분 분석은 정확하지는 않으나 비교적 타당한 결과를 보여주었으며, 이때 분석의 정확도를 높이기 위해서는 레퍼런스 이미지의 수량을 확보하고 데이터셋의 간격을 촘촘하게 설정하는 것이 중요하다고 판단된다.
Acknowledgements
이 논문은 2018학년도 조선대학교 학술연구비의 지원을 받아 연구되었습니다.